写在前面的话
本章的内容相对较多,核心述求就是一个,当文档返回极多时,从什么维度来对文档进行评分
文档评分、词项权重计算及向量空间模型
当满足要求的文档结果极多时,就需要对文档进行评分和排序
参数化索引及域索引
元数据
和文档有关的一些特定形式的数据,例如文档的作者,标题及出版日期等
域
内容可以是任意的自由文本
字段
和域类似,只是字段通常的取值可能性较小
通常可以将文档的标题和摘要看做域
例如:
查询标题中出现merchant,作者中存在william且正文中存在短语gentl rain的文档,就需要如下的倒排索引
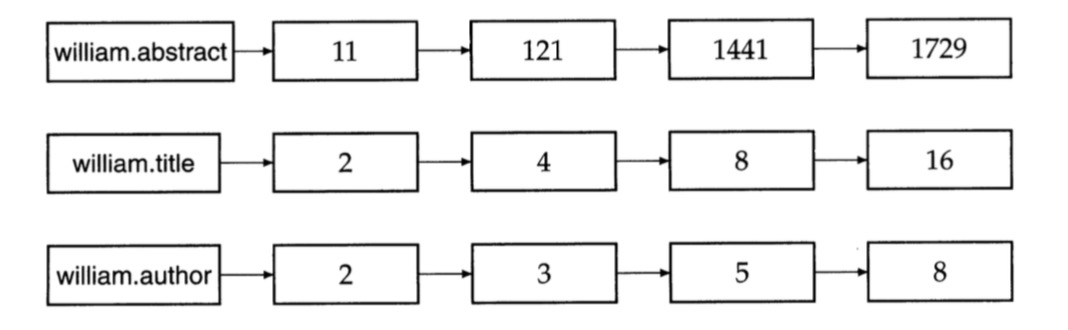
同样,可以通过域编码来减少倒排索引的规模,例如将title和author编码到一起

编码的好处
- 减少内存占用
- 支持域加权评分技术
域加权评分
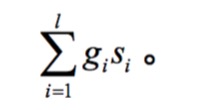
其中:
- gi每个域对应的权重
- si查询与第i个域的匹配得分(1为匹配上,0为未匹配上)
该方法也称为排序式布尔检索
实现:
一种简单的方法:依次扫描每篇文档并为之评分
通过倒排索引直接计算的方法:

上述算法的场景:两个词存在AND关系,计算文档的得分
整体做法和之前倒排索引的交集查找基本一致,只是在过程中增加了一个评分累加器(score[])
权重学习
通过机器学习来确定权重,整体方法如下所示:
- 给定训练样本,每个样本可以表示成一个三元组<查询q,文档d,q和d的相关性判断>
- 利用上述样本集合学习到权重gi
将权重学习问题转化成为优化问题:
举例
场景:
- 每篇文档只包含title域和body域
- 给定查询q和文档d
- St(d,q)和Sb(d,q)是查询分别对于title域和body域的布尔匹配变量
最后的得分如下所示:
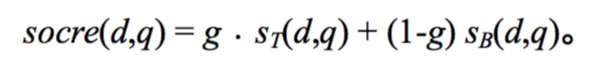
对于每个训练样本,可以人工得到结果r(dj,qj)。那么问题就转变成为了,要得到一个g,使所有样本的误差的和最小
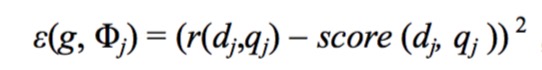
最优权重g的计算

词项频率及权重计算
词项在文档或者域中出现频率越高(tf),该文档或者域的得分越高
逆文档频率
某些词项对于相关度计算来讲几乎没有或者很少有区分能力,例如对于汽车行业的文档,每一篇都包含auto,因此需要机制来降低这些出现次数过多的文档的影响
直接的想法:给文档集频率(cf)较高的词项赋予较低的权重
文档集频率:词项在文档集中出现的次数
实际中更常用到的是文档频率(df)
文档频率:出现词项的文档的数量
df的映射方法:
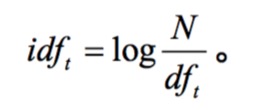
- 所有文档的数量为N
- 词项t的逆文档频率为idf
因此,罕见词的idf较高,高频词的idf较低
tf-idf权重计算
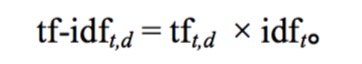
- 词项t只在少数几篇文档多次出现时,权重最大
- 当t在一篇文档中出现次数很少,或者在很多文档中出现,权重取值次之
- t在所有文档中都出现,权重取值最小
这样,可以将每个文档都看做一个向量,每个分量都对应词典的一个词项,分量值为tfidf值,当没有出现,分量为0
这样,文档d的得分如下
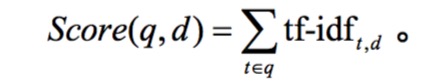
- q是指查询
- t是属于查询中的词项
向量空间模型
内积
假设:
- 文档对于的向量为V(d)
- V(d)中的分量为tf-idf权重计算方式
相似度计算:
向量差的向量大小
- 劣势:差向量可能很大,因为文档长度差距很大
通常是使用余弦相似度
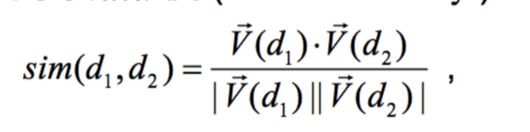
- 分子是向量的内积
- 分母是向量的欧几里得长度的乘积
也可以重写为欧式归一化
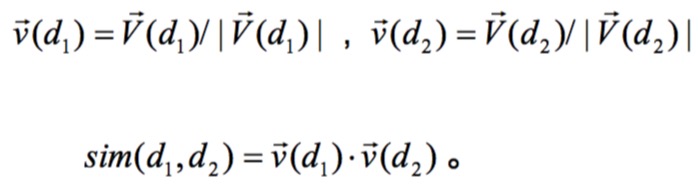
相似度可以理解成两个单位向量的余弦
查询向量
将查询也转换成一个单位向量,再将查询的单位向量与各个文档内积,就能得到分数排名
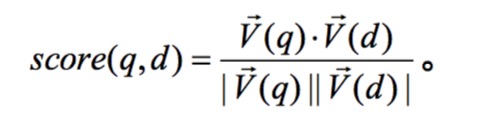
接下来,整个检索过程可以变成:
计算查询向量与每个文档向量的余弦相似度,并选择得分最高的K篇文档。
向量相似度计算

其中
- Length是文档的长度
- Score是文档的得分
问题:权重存储需要浮点数,很占据空间
方法:
- 不需要提前计算idf,只需要将N/df存储在t对应的倒排记录的头部
- 倒排记录最后只需要排名前K的结果,因此可以直接建立一个大顶堆来实现
其它tf-idf的计算方法
tf的亚线性尺度变换方法
tf的频率出现20次的单词并非重要性是出现1次的20倍,因此这里会做一个换算,通常的换算方法如下
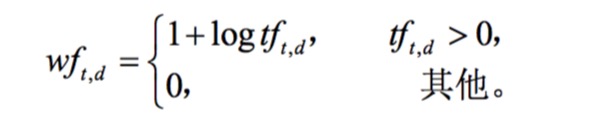
之后可以用wtf来替换之前的tf
基于最大的tf进行归一化
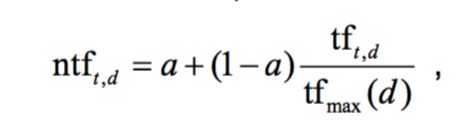
- a:阻尼系数,取值范围为0~1,通常取0.4
- tfmax(d):最大词的词项频率
- t:每个词项
使用注意事项:
- 停用词表会引起权重的显著变化
- 文档可能包含异常词项,数量过多
- 如果某篇文档词项更均匀,那么需要区别对待
文档权重和查询权重机制

文档长度的回转归一化
基于欧式长度的归一化会损失一些文档的细节,例如
- 长文档包含更多的词项,因此词项频率tf会更高
- 长文档包含更多的不同的词项,因此词汇量会更大
这里提出了一种更折中的方法,回转文档长度归一化,有兴趣可以去阅读原文