写在前面的话
本文是信息检索导论的第五章,压缩部分,本文主要内容如下
- 索引压缩
- 倒排记录表压缩
对于索引压缩主要是采用的将词项放在同一字符串,减少指针,再对重复的前缀进行编码
对于倒排记录表就是通过编码来压缩倒排记录表的数字
整体内容上比较晦涩,对于编码技术兴趣不大的人看起来会比较头疼,我也是很迅速的过了这一章
索引压缩
压缩的优点:
- 节省磁盘空间
- 增加高速缓存的利用率
- 加快磁盘到内存的传输速度
信息检索中词项的统计特性
Heap定律:词项数目的估计
Heaps定律
1 | M = kT^b |
- T:文档集合中词条的个数
- M:词项数目
- k >= 30 && k <= 100
- b = 0.5
Heap定律的假设:
- 随着文档数目的增加,词汇量会持续增长而不会稳定到一个最大值
- 大规模文档集的词汇量也会非常大
Zipf定律:对词项分布的建模
如果t1是文档集中出现最多的词项,t2是文档集中的出现第二多的词项,那么排名第i多的词项的文档集频率cfi与1/i成正比
词典压缩
词典压缩的最主要目的是将词典放入内存中
将词典看成单一字符串的压缩方法
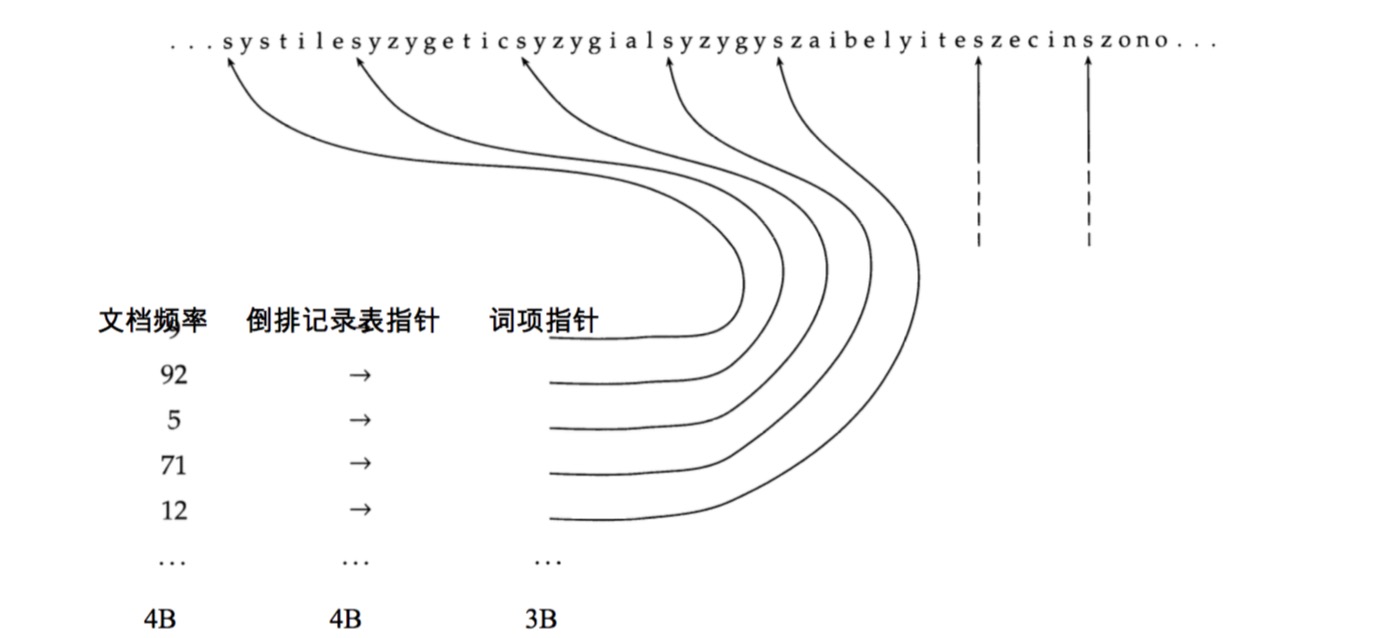
- 将所有词项压缩成一个字符串
- 每个词项增加一个定位指针
- 通过二分查找来定位所需的词项
按块存储

- 只保留每个块开始的指针
- 在词项开始的地方增加词项的长度存储
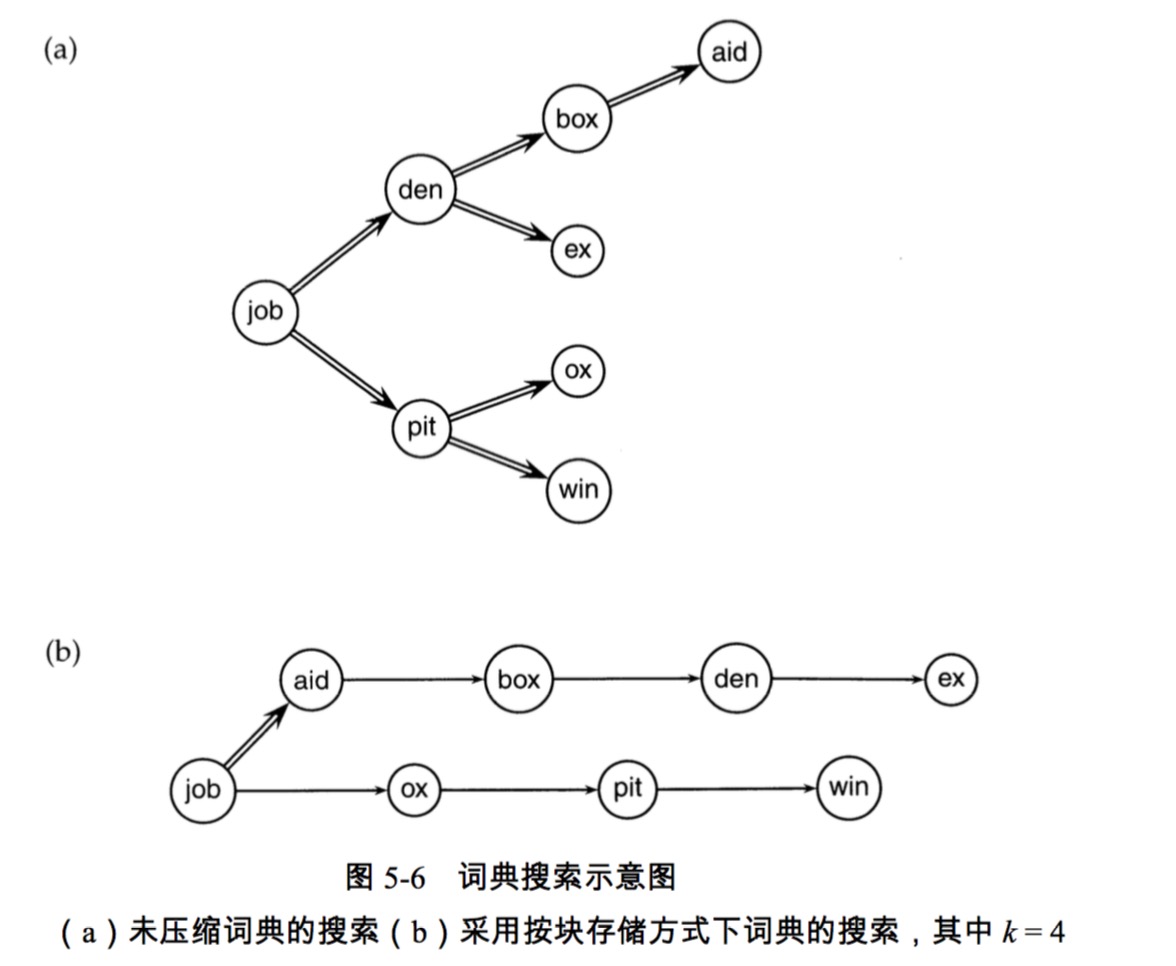
块中词项越多,压缩率越大,但是查找会更缓慢
另外,使用前端编码技术(front coding),可以对词项的公共前缀进行压缩,进一步缩小词项大小。
倒排记录表的压缩
思路:对小数字采用比大数字更短的编码方式
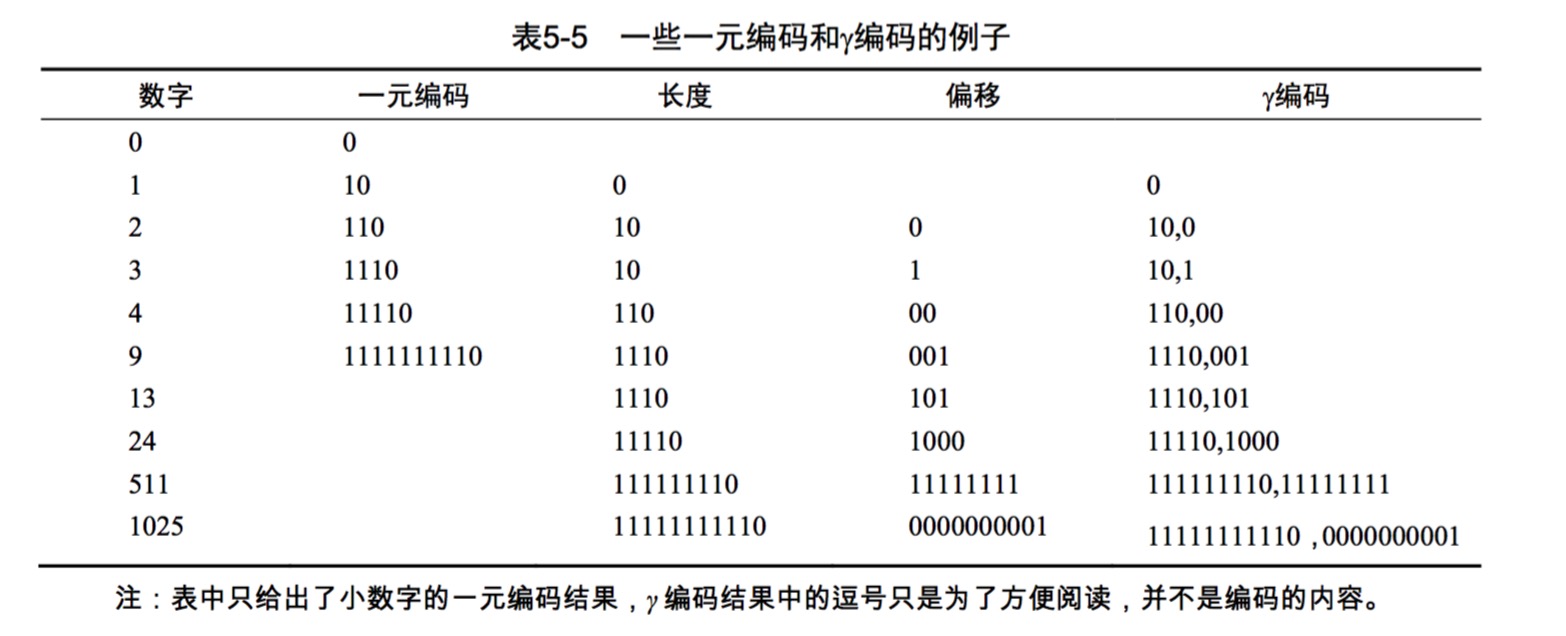
可变字节码
VB编码(Variable byte,可变字节)利用整数个字节来对间距编码
y编码
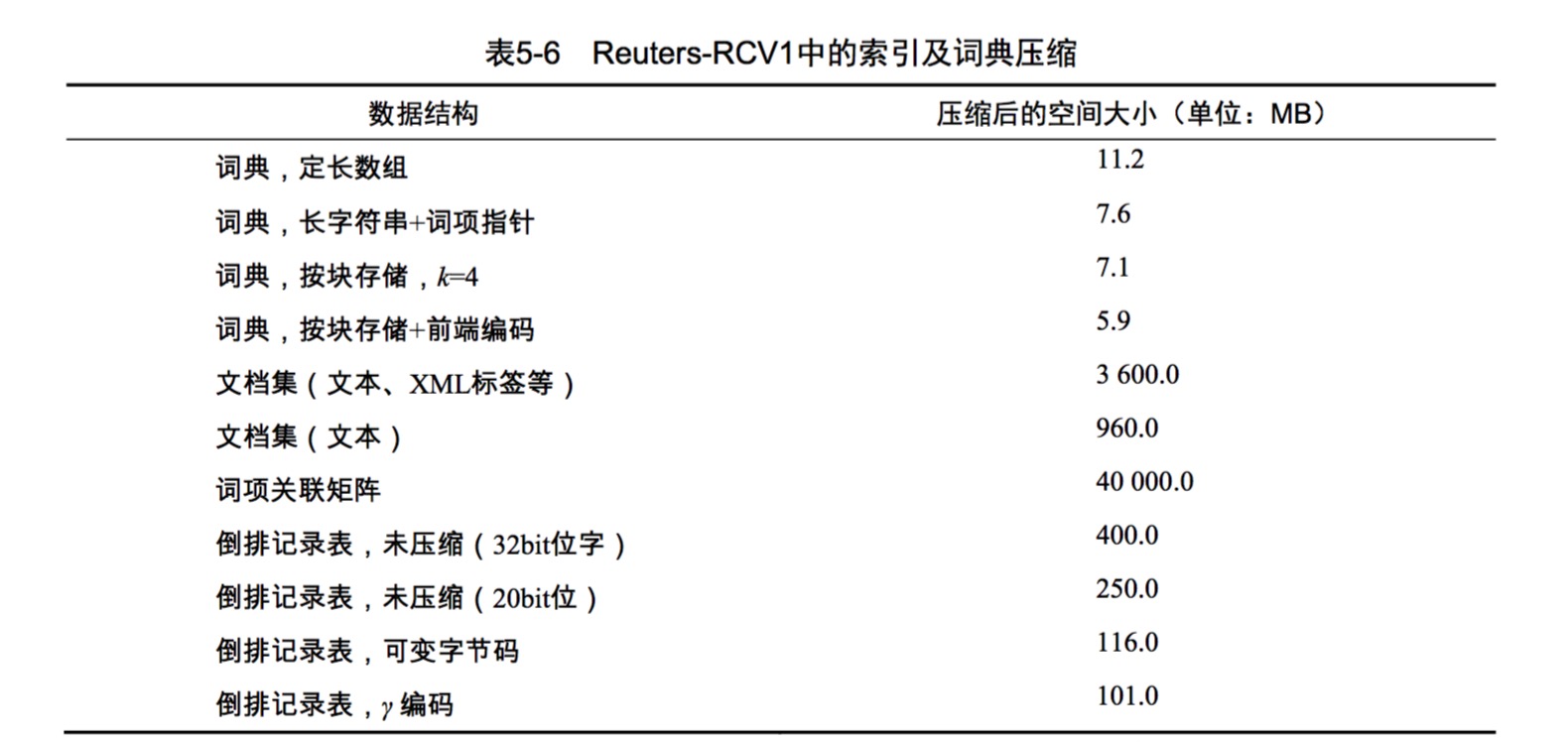
采用了y编码后,在本文提到的所有压缩方式效果如下所示: