写在前面的话
本文是《信息检索导论入门》第四章,本文主要的内容如下:
讨论了在大文件读写下的索引构建的方法
- BSBI,基于块的索引排序
- SPIMI,内存式单遍扫描索引算法
分布式索引构建
- 动态索引构建
- 索引的权限构建
整体内容不算多,还比较好理解,除了mapReduce那部分,确实没玩过。
索引构建
硬件基础
本部分内容参见计算机体系结构,更详尽一点
简而言之
- 访问内存远快于访问磁盘
- 进行磁盘读写时,磁头移动到数据所在磁道需要一段时间,大概5ms(寻道时间)
- 操作系统以数据块为读写单位
- 数据从磁盘读写数据到内存是由数据总线完成,这意味着在I/O处理时处理器可以处理数据
- IR系统的内存通常几十G,硬盘比内存大几个数量级
基于块的排序索引方法
为使构建更加高效,使用ID来代替字符串作为索引
BSBI( blocked sort-based indexing algorithm,基于块的索引排序技术)
- 将文档分割成几个大小相等的部分
- 将每个部分的词项ID-文档ID对排序
- 将中间产生的临时文件存在磁盘
- 将所有中间文件合并成最终索引
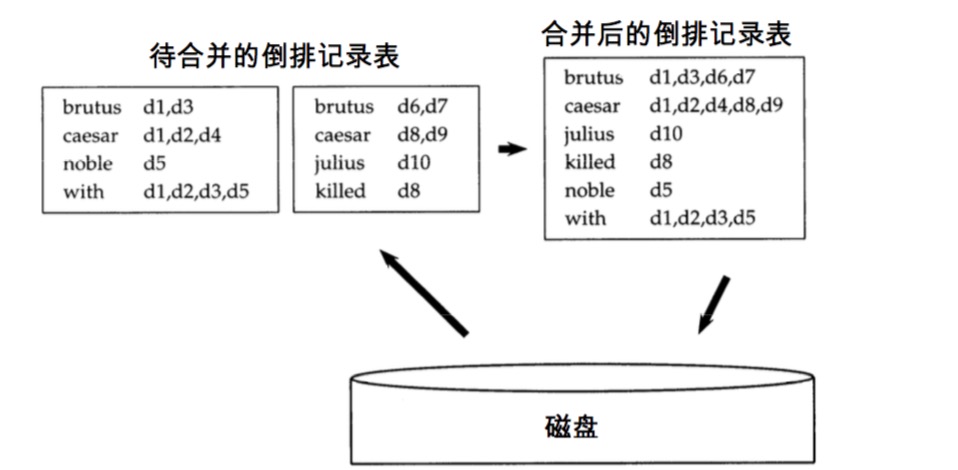
合并方法:
- 先将每个临时文件进行合并,成一个部分倒排索引
- 使用堆每次输入最小的词项进行排序归并,将结果写入磁盘
问题:
需要构建词项ID与词项的对应表,这个表如果过大将无法放在内存中
内存单遍扫描索引构建方法
SPIMI(single-pass in-memory indexing,内存式单遍扫描索引算法)
将每个快的词典写入磁盘,对于下个快就采用新的词典

算法说明:
- 算法逐一处理词项-文档ID对。
- 词项第一次出现则加入词典,建立新的倒排索引记录表
- 返回其倒排记录表
- 直接在记录表插入词项-文档ID(可能需要动态调整大小)
- 内存耗尽前进行词典顺序排序
- 写入磁盘
优势:
- 不需要对词项ID-文档进行排序
- 所有操作和文档大小成线性关系
分布式索引构建方法
对于很大的索引,无法在单台机器上完成,就需要引入集群构建分布式索引,这里介绍的是MapReduce的一个应用
此处详见ddia的流处理的部分,更加详尽
动态索引构建方法
需求:对于索引需要动态更新
简单方法:
- 周期性的对文档集从头到尾进行索引构建
新需求:及时能查询到新文档
- 保持大的主索引
- 小的用于存储更新文档的索引存放在内存中
- 检索遍历两个索引并将结果合并
- 文档删除记录一个无效标记用于过滤
- 文档更新用先删除后插入实现
- 辅助索引变大就进行合并
合并方法:
对数合并

算法描述:
- 将索引增加到内存索引Z0中
- 当len(Z0) = n时,进行合并
- 当Ii在index中存在,则进行合并
- 当Ii在index中不存在,则合并,并且添加到index中
劣势:
- 会增加全局统计信息的复杂度
- 维护,查询,分布等的复杂度都会增加
其它索引类型
这里讨论的方法都能用于位置索引上
安全性讨论:
- 限制不同用户搜索不同内容
- 文档本身也有是否需要公开的限制
方法:
- 通过ACL(access control list,访问控制表)实现
- ACL生成一个用户访问文档权限的倒排记录表
- 搜索结果和这边表求交集运算
劣势:
- 维护表较为困难