写在前面的话
本文主要内容是信息检索导论的第三章部分,包含如下内容:
- 词典搜索
- 容错(单词容错与上下文容错)
这里面提到了k-gram这种方法,直观上的感觉有点像之前的短语搜索,本章的内容整体来看是比较容易理解的
词典及容错式检索
本章主要介绍对查询中存在拼写错误或存在不同形式具有鲁棒性的拼写校对技术
词典搜索的数据结构
词汇表的查找通常使用一种叫做词典的结构
- 哈希表
- 搜索树
选择具体方案时需要考虑
- 关键字的数量
- 关键字的数量是固定的还是变化的,在变化得情况下是只插入新关键字,还是同时删除旧的关键字
- 不同关键字的相对访问频率如何
哈希表
方法:
- 每个词项通过哈希函数映射成一个整数
- 映射函数目标空间需要大,减少哈希结果冲突的可能性
- 对每个查询项进行哈希操作,解决潜在冲突
劣势:
- 难以处理词项稍微变形的情况
- 难以处理前缀型查询
- 在词汇表增长的情况下,哈希函数会在几年内失效
搜索树
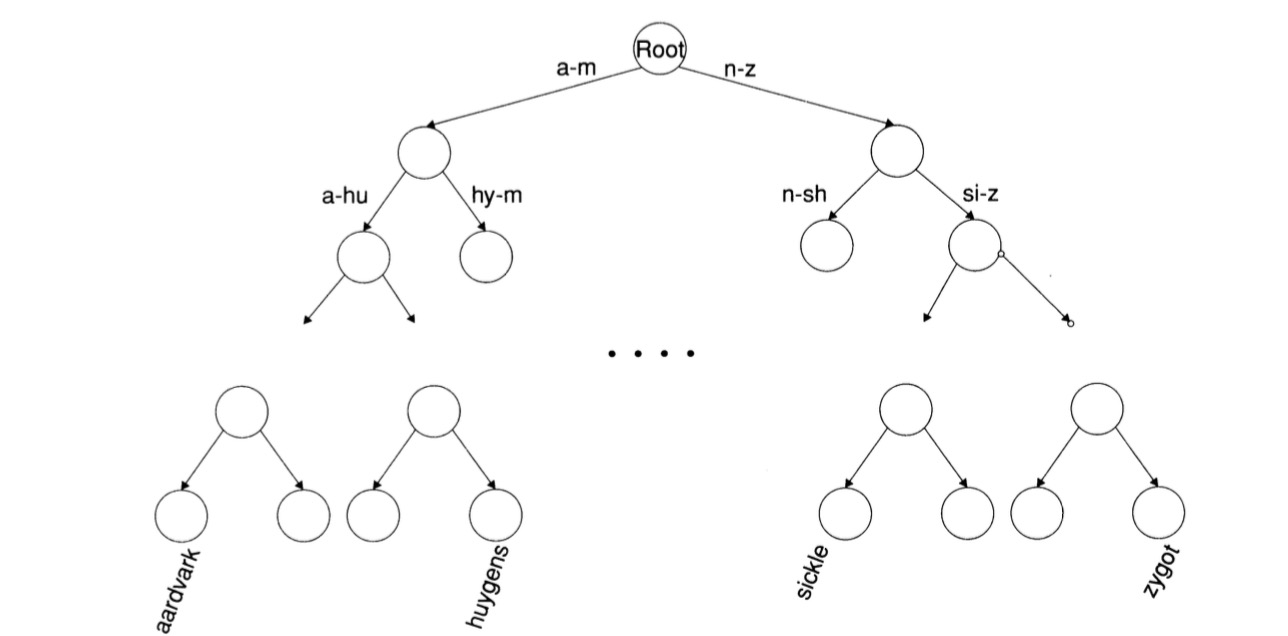
二叉树的平衡性是实现高效搜索的关键
方法:
允许内部子树的数目在某个固定区间内变化,例如词典搜索中普遍使用的B-树
通配符查询
适用场景:
- 对查询的拼写不太确定
- 某个查询词项可能有不同的拼写版本
- 查询某个词项的所有变形
- 不确定一个外来词或短语的正确拼写形式
尾通配符查询
- 按照字符在字典树中获得所有满足的词的集合
- 按照集合对倒排索引中找到所有的词
通配符不在尾部
引入词典的反向B-树,例如,lemon在反向B-树的路径就是n-o-m-e-l。
方法:
- 执行正向B-树,得到集合|W|
- 执行反向B-树,得到集合|R|
- 对|W|与|R|求交集,即可
- 对交集在倒排索引中进行查找即可
一般通配符查询
轮排索引
- 引入结束符号
$ - 构建轮排索引
- 将通配符轮排到结尾
- 在轮排索引中查询该字符串
- 对于多个通配符进行后续过滤
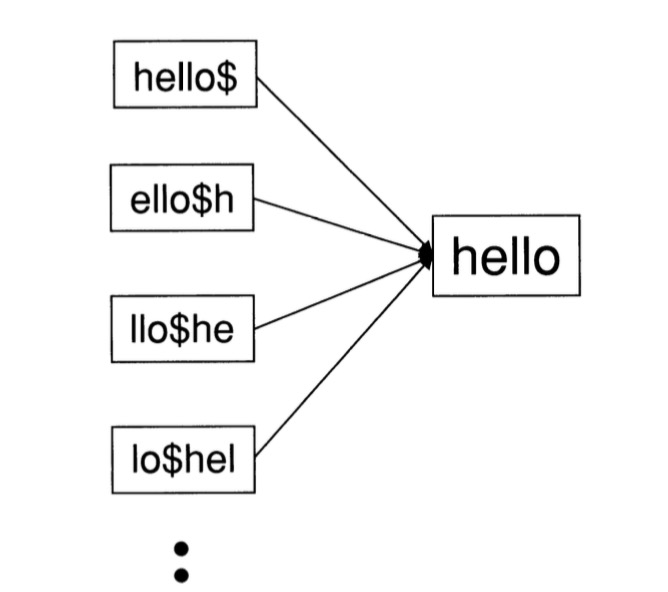
轮排索引的缺点在于词典会变得非常大,因为保存了轮排的结果
支持通配符查询的k-gram索引
k-gram
表示由k个字符组成的序列
k-gram索引
词典由词汇表中所有词项的所有k-gram形式构成
每个倒排记录由包含该k-gram的词项组成

查询方法:
例如词语re*ve:
- 即可构造bool查询”$re” AND “ve$”
- 后过滤,使用原始的查询字符串对结果进行过滤
拼写校正
本部分关注查询的拼写校正问题
拼写校正的实现
基本原则
- 对于一个拼写错误的查询,在其可能错误的拼写中,选择最“近”的一个
- 当两个正确拼写查询临近度差不多时,选择更常见的那个。
通常的用户返回:
- 查询carot,返回carot文档,也返回拼写校正后的文档(如carrot和tarot等)
- 当carot不在字典中,采用方法1
- 当原始查询返回结果少于预定,采用方法1
- 搜索界面中给用户提供拼写建议,询问用户“你是否在查找carrot”
拼写校正的方法
- 词项独立校正:校正词项是独立的,每次只考虑一个词项的改正
- 上下文敏感校正
编辑距离
编辑距离
将s1替换成s2需要的最小操作数
编辑操作包括
- 字符插入
- 字符删除
- 字符替换
还可以考虑编辑权重,例如s替换成p将比s替换成a权重更小,因为s与a更接近

字符串距离编辑算法如上所示
这里的做法和最长子序列的做法很接近
首先寻找通项公式:
1 | Aij = min(Aij-1 +1, Ai-1j + 1, Ai-1j-1 + tmp) |
其中
- Aij表示字符串s1的前i个字母与s2的前j个字母的距离
- 当s1的i字母与s2的字母相同时,tmp取值为0,否则为1
即可通过一个二维矩阵计算出字母间的距离。
https://leetcode-cn.com/problems/edit-distance/comments/
在字符表中寻找编辑最小字符串的方法:
- 穷举法(计算表中每个字符到查询字符的距离,再选最小)
- 限制在有相同首字母的字符串上
- 利用轮排索引
拼写校正中的k-gram索引
方法:
- 查询匹配某个固定数量的k-gram即可
- 通过雅可比系数进行修正
雅可比系数计算公式:|A 交集 B| / |A 并集 B|
例如
- 查询词为bord,那么其2-gram为 bo, or和rd
- 假设词库中的总长度为8
- 对于匹配到的boardroom,其雅可比系数为2/(8+3-2)
上下文敏感的拼写校正
一种简单的实现方式:
对每个单词都去匹配可能的拼写正确词
一种启发式方式:
对词语扩展时只保留词库中的高频组合结果
基于发音的校正技术
思路:
对于每个词项,进行一个语音哈希操作,发音相似的词项都被映射为同一个词
通过语音哈希的算法被称为soundex算法,算法构建如下:
- 将所有词项转变为四字符的简化形式。基于这些简化形式建立原始的倒排索引,称为soundex索引
- 对查询词项进行相同操作
- 当查询进行soundex匹配时,在soundex索引中进行
四字符的转化方法如下:
- 保留词项的首字母
- 对后续字母进行转化
- 将后续的所有的A、E、I、O、U、H、W及Y变为0
- B、F、P和V转为1
- C、G、J、K、Q、S、X和Z转为2
- D、T转为3
- L转为4
- M、N转为5
- R转为6
- 将连续出现的两个字母转化为1个字母
- 在结果字符串中删除0,并在字符串结尾补足0,返回前4位,该结果为一个字母,3个数字