写在前面的话
本文是教材《信息检索导论》的第一章的内容,布尔检索,整体来说是比较简单的。
本章主要是两个部分:
- 倒排索引的构建
- 布尔查询的处理及优化
入门初步了解下,这次这个系列预计将本书的1~8章进行学习,good luck。
布尔检索
信息检索是从大规模非结构化数据(通常是文本)的集合(通常保存在计算机上)中找出满足用户信息需求的资料(通常是文本)的过程。
一个信息检索的例子
grepping:线性扫描
然而,在如下现实条件中,线性扫描不再适用
- 大规模文件集条件下的快速查找
- 灵活的匹配方式,例如 Romans NEAR countrymen
- 需要对结果进行排序
索引
以莎士比亚全集检索为例
- 对每篇文章都记录是否包含某个词(词项文档关联矩阵)
- 行向量:表明词在某文章中出现或不出现
- 列向量:表明文章是否包含某词
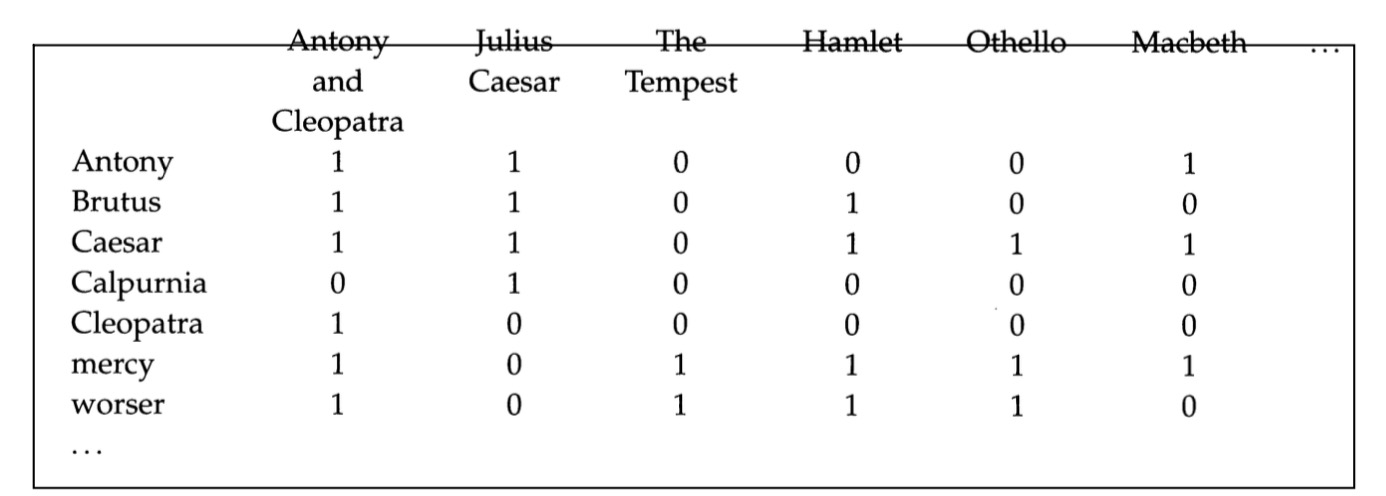
计算查询 Brutus AND Caesar AND NOT Calpurnia
- 取出
Brutus、Caesar以及对Calpurnia行向量取反,做与操作,就可以得到结果
对于真实场景
建立词项-文档矩阵过大,并且这是一个稀疏矩阵,因此只存储原始矩阵中1的位置会更好
倒排索引
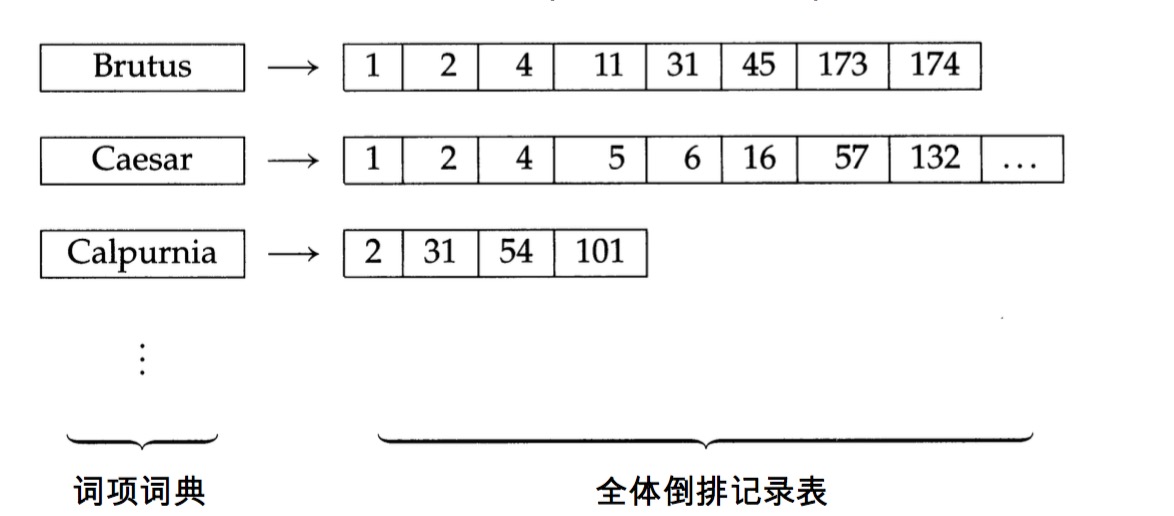
如上图所示:
- 左侧:词项词典
- 右侧:倒排记录 e:倒排记录表,以文档id进行排序
构建倒排索引初体验
步骤
- 收集需要构建索引的文档
- 将文档转化为词条列表
- 语言学预处理,产生归一化词条
- 对于词项建立倒排索引
本部分假定词条已经产生,开始建立倒排索引
- 将归一化词条按照字母顺序进行排序
- 排序后进行合并,形成索引
- 词典中还会记录每个词项的频率(也既是长度)
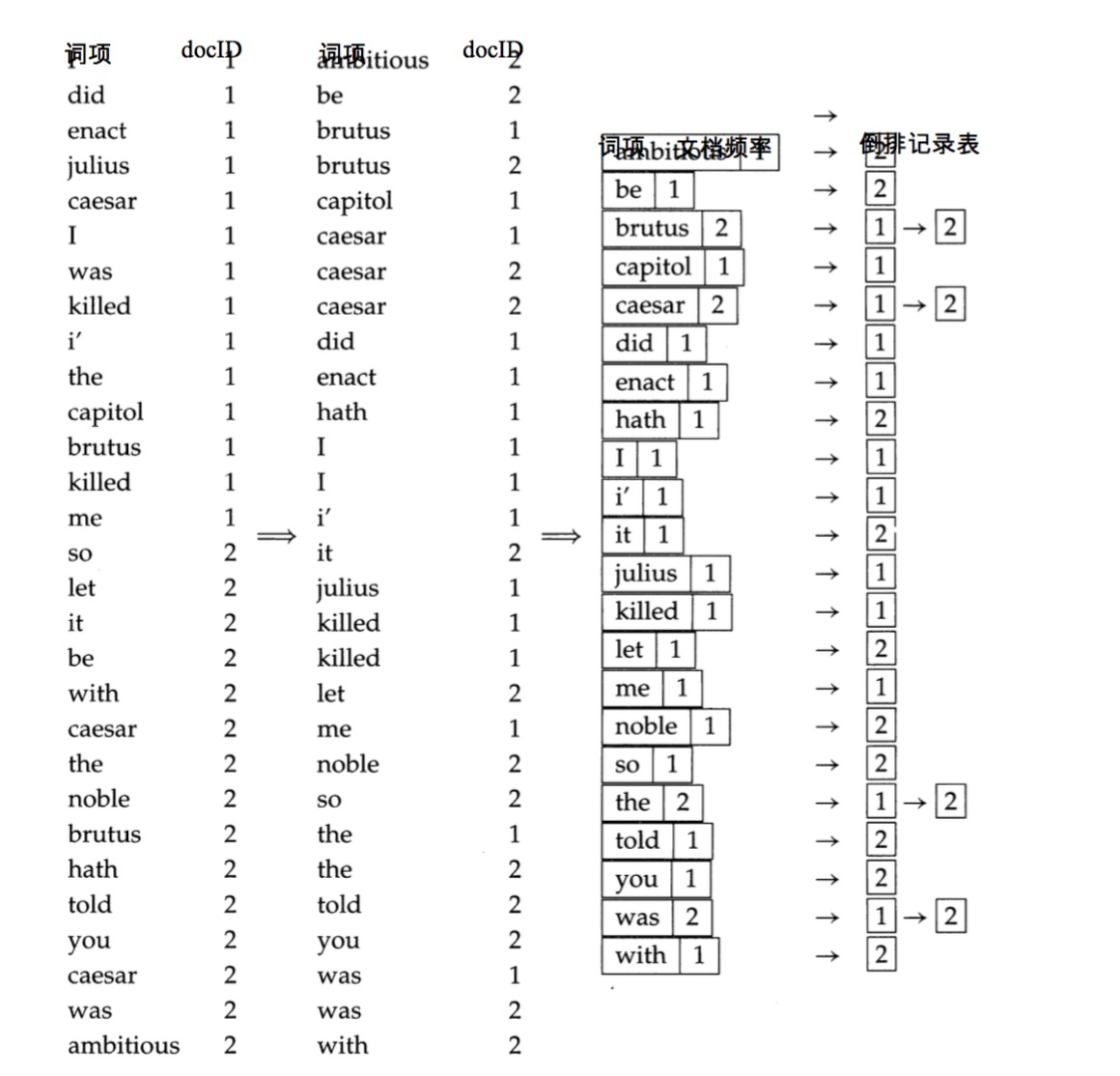
- 词典通常放在内存中
- 倒排记录表通常放在硬盘中
- 单链表
- 变长数组
布尔查询的处置
简单步骤
以简单的与操作为例1
Brutus AND Calpurnia
- 在词典中定位Brutus
- 返回其倒排记录表
- 在词典中定位Calpurnia
- 返回其倒排记录表
- 对两个倒排记录表求交集
一个简单有效的求交集算法

优化
以与操作为例
1 | Brutus AND Caesar AND Calpurnia |
一个比较直接的思路是,选择频率较小的元素优先进行操作,这样得到的中间结果更小。
算法如下:

- 选取频率最小的元素
- 进行计算,并且得到剩下的元素
- 重复前两步,直到剩下没有元素,返回结果
对基本布尔操作的扩展及有序检索
布尔操作的普遍问题:
- AND操作产生的结果正确率高,但是召回率偏低
- OR操作产生的结果召回率高,但是正确率低