写在前面的话
本文是该系列的第二篇文章,详细一点的介绍了协同过滤的方法和原理,包括User CF和Item CF,并且给出了基于 Apache Mahout的一个实践。实践部分暂时还未关注,只是关注了目前的原理部分,感觉整体思路还是很清晰的,理解也不困难。
集体智慧和协同过滤
集体智慧
集体智慧是指在大量的人群的行为和数据中收集答案,帮助你对整个人群得到统计意义上的结论,这些结论是我们在单个个体上无法得到的,它往往是某种趋势或者人群中共性的部分。
Wikipedia和Google是两个典型的利用集体智慧的 Web 2.0 应用
什么是协同过滤
协同过滤是利用集体智慧的一个典型方法。
协同过滤一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目录作为推荐给你。
核心问题:
- 如何确定一个用户是不是和你有相似的品位?
- 如何将邻居们的喜好组织成一个排序的目录?
深入协同过滤的核心
步骤
- 收集用户偏好
- 找到相似用户或物品
- 计算推荐
收集用户偏好
用户行为和用户偏好
| 用户行为 | 类型 | 特征 | 作用 |
|---|---|---|---|
| 评分 | 显式 | 整数量化的偏好,可能的取值是 [0, n];n 一般取值为 5 或者是 10 | 通过用户对物品的评分,可以精确的得到用户的偏好 |
| 投票 | 显式 | 布尔量化的偏好,取值是 0 或 1 | 通过用户对物品的投票,可以较精确的得到用户的偏好 |
| 转发 | 显式 | 布尔量化的偏好,取值是 0 或 1 | 通过用户对物品的投票,可以精确的得到用户的偏好。如果是站内,同时可以推理得到被转发人的偏好(不精确) |
| 保存书签 | 显式 | 布尔量化的偏好,取值是 0 或 1 | 通过用户对物品的投票,可以精确的得到用户的偏好。 |
| 标记标签 (Tag) | 显式 | 一些单词,需要对单词进行分析,得到偏好 | 通过分析用户的标签,可以得到用户对项目的理解,同时可以分析出用户的情感:喜欢还是讨厌 |
| 评论 | 显式 | 一段文字,需要进行文本分析,得到偏好 | 通过分析用户的评论,可以得到用户的情感:喜欢还是讨厌 |
| 点击流 ( 查看 ) | 隐式 | 一组用户的点击,用户对物品感兴趣,需要进行分析,得到偏好 | 用户的点击一定程度上反映了用户的注意力,所以它也可以从一定程度上反映用户的喜好。 |
| 页面停留时间 | 隐式 | 一组时间信息,噪音大,需要进行去噪,分析,得到偏好 | 用户的页面停留时间一定程度上反映了用户的注意力和喜好,但噪音偏大,不好利用。 |
| 购买 | 隐式 | 布尔量化的偏好,取值是 0 或 1 | 用户的购买是很明确的说明这个项目它感兴趣。 |
组合用户行为的方式
- 将不同的行为分组:一般可以分为“查看”和“购买”等等,然后基于不同的行为,计算不同的用户 / 物品相似度。 类似于“购买了该图书的还购买了…”,“查看了该图书的还查看了…”
- 根据不同行为反映用户喜好的程度将它们进行加权,得到用户对于物品的总体喜好
收集完成后,还需要对数据进行预处理,核心就是减噪和归一化
- 减噪:通过经典的数据挖掘算法过滤掉行为数据中的噪音,使分析更加精确
- 归一化:如何将各个行为的数据统一在一个相同的取值范围中,从而使得加权求和得到的总体喜好更加精确,就需要进行归一化处理。最简单的归一化就是将各类数据除以此类中的最大值,以保证归一化后的数据取值在 [0,1] 范围中。
完成预处理后,可以得到一个用户偏好的二维矩阵,一维是用户列表,一维是物品列表,值是用户对物品的偏好,一般是[0,1]或者[-1,1]的浮点数
找到相似的用户或物品
得到用户喜好后,可以根据用户喜好计算相似用户和物品,然后基于相似用户或者物品进行推荐。
这就引出问题了,如何计算相似度
相似度的计算
本质上都是计算两个向量的距离
欧几里得距离
- 用于计算欧几里德空间中两个点的距离
- 假设x,y是n维空间的两个点,那之间的欧几里得距离是:
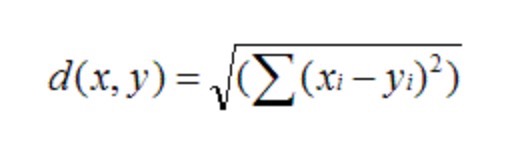
- 最后再进行转换
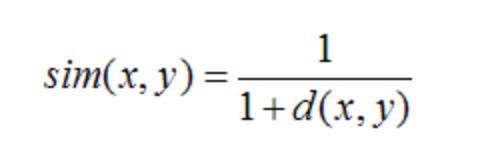
皮尔逊相关系数
一般用于计算两个定距变量间联系的紧密程度,取值在[-1,+1]之间。
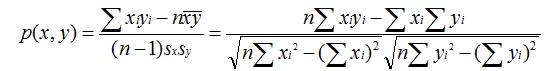
其中,sx和sy是x和y的样品标准偏差
Cosine 相似度
被广泛应用于计算文档数据的相似度
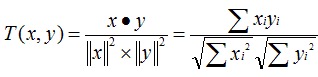
Tanimoto系数
也称为Jaccard系数,是Cosine相似度的扩展,也多用于计算文档数据的相似度:
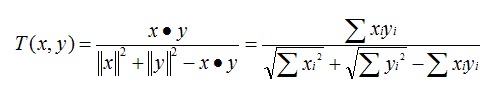
相似邻居的计算
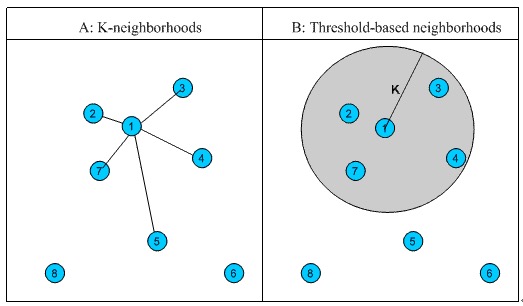
固定数量的邻居:K-neighborhoods 或者 Fix-size neighborhoods
方法:
- 不论邻居远近,只选最近的K个作为邻居
坏处:
- 对于孤立点不友好,被迫选取一些不太相似的点作为邻居, 影响了邻居相似的程度
基于相似度门槛的邻居:Threshold-based neighborhoods
基于相似度门槛的邻居计算是对邻居的远近进行最大值的限制,落在以当前点为中心,距离为 K 的区域中的所有点都作为当前点的邻居,这种方法计算得到的邻居个数不确定,但相似度不会出现较大的误差。
计算推荐
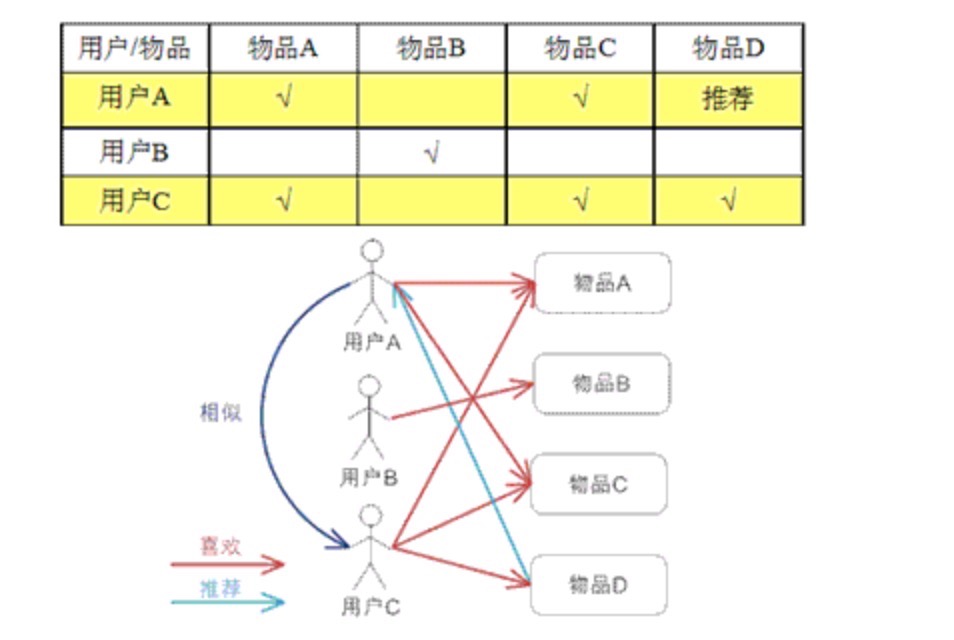
基于用户的CF(user CF)
思想:
- 基于用户对物品的偏好找到相邻邻居用户
- 将邻居用户喜欢的推荐给当前用户
计算:
- 将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度
- 找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好
- 预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐
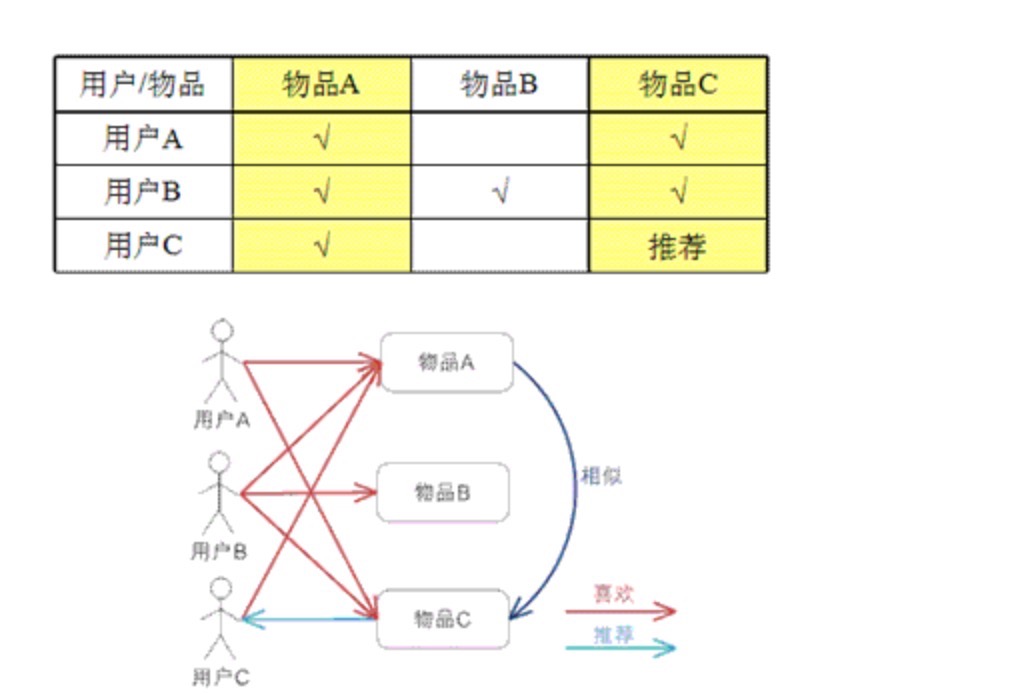
基于物品的CF(Item CF)
基于物品的 CF 的原理和基于用户的 CF 类似
计算:
- 将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度
- 根据用户历史的偏好预测当前用户还没有表示偏好的物品
基于用户的CF 与 基于物品的CF 的对比
计算复杂度
在不同的系统中各有优势
- 当用户数量大大超过物品数量时,Item CF表现更优秀
- 当物品数量大大超过用户数量时,User CF表现更优秀
适用场景
- 非社交网络网站中:内容内在联系是更有效的推荐原则,Item CF更为适用
- 社交网络站点中:User CF是一个更不错的选择
推荐多样性和精度
推荐多样性的度量方法:
- 从单个用户的角度度量:给定一个用户,查看系统给出的推荐列表是否多样,也即是比较推荐列表中物品之间两两的相似度。Item CF用户多样性显然不如User CF
- 考虑系统的多样性,也被称为覆盖率:是指一个推荐系统是否能够提供给所有用户丰富的选择。Item CF系统多样性优于User CF,因为能推荐更多新颖的物品。
举例:
- 场景:某用户喜欢领域A、B、C,其中A是主要喜欢的
- User CF会推荐A、B、C中热门的物品给用户
- Item CF只会推荐A领域的东西给用户
实际中,结合User CF和Item CF是最优的选择。
用户对推荐算法的适应度
- 对于User CF:推荐的原则是假设用户会喜欢那些和他有相同喜好的用户喜欢的东西,因此用户的适应度是和他有多少共同喜好用户成正比
- 对于Item CF:推荐的原则是假设用户会喜欢和他以前喜欢的东西相似的东西,因此用户的适应度是和他喜好物品的自相似度大小程度成正比。
基于 Apache Mahout 实现高效的协同过滤推荐
本部分暂略