写在前面的话
极有可能未来会不再从事区块链行业了,歇息一下
本文的主要内容来自于 https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/ ,可以算是对这个内容阅读后的读书记录。
推荐搜索以前一直是个用户和吐槽役的身份,吐槽买了包子又给我推荐馒头,吐槽淘宝搜过情趣内衣之后微博推荐全是情趣内衣。现在可能会成为被吐槽的对象了,还是按照之前的学习思路,先看看目录,了解下大纲,看看未来到底要面对什么。
推荐引擎初探
本部分将深入介绍推荐引擎的工作原理,和其中涉及的各种推荐机制,以及它们各自的优缺点和适用场景,帮助用户清楚的了解和快速构建适合自己的推荐引擎。
推荐引擎
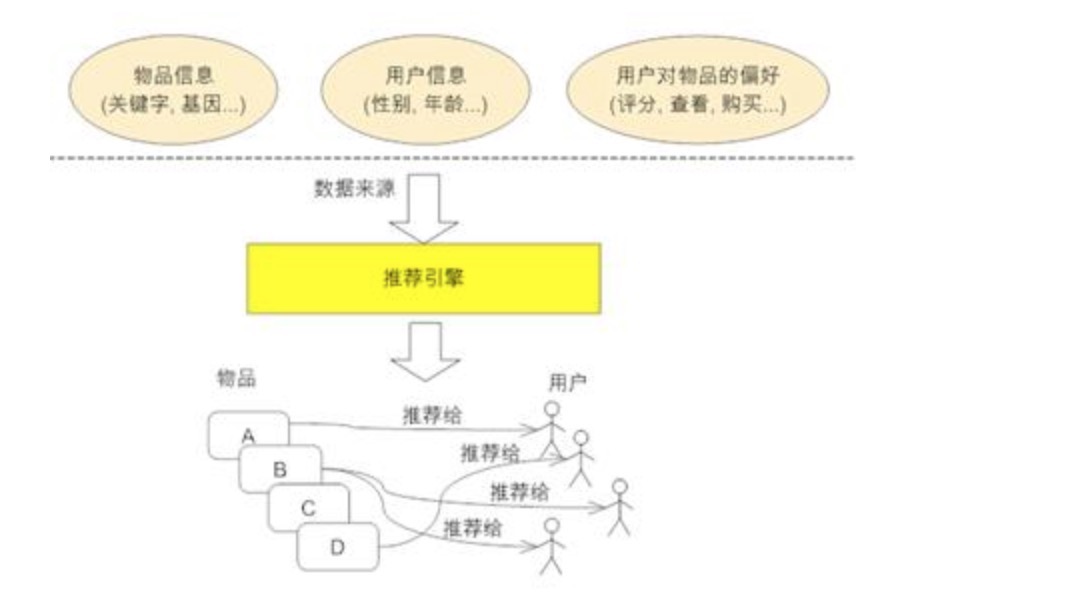
这里将推荐引擎看作黑盒,一般来说输入数据源包括:
- 要推荐物品或内容的元数据,例如关键字,基因描述等;
- 系统用户的基本信息,例如性别,年龄等
- 用户对物品或者信息的偏好。其实这些用户的偏好信息可以分为两类:
- 显式的用户反馈:这类是用户在网站上自然浏览或者使用网站以外,显式的提供反馈信息,例如对物品的评分,评论
- 隐式的用户反馈:这类是用户在使用网站是产生的数据,隐式的反应了用户对物品的喜好,例如购买了某物品,查看了某物品的信息
显式的用户反馈能准确的反应用户对物品的真实喜好,但是需要用户行动
隐式的用户行为,通过一些分析和处理,也能反映用户的喜好,只是数据不是很精确,有些行为的分析存在较大的噪音
推荐引擎的分类
推荐引擎是不是为不同的用户推荐不同的数据
- 根据大众行为的推荐引擎:对每个用户都给出同样的推荐,可以静态设置,也可以由系统计算出当下流行
- 个性化推荐引擎:对不同的用户,根据他们的口味和喜好给出更加精确的推荐
根据推荐引擎的数据源
- 根据系统用户的基本信息发现用户的相关程度,这种被称为基于人口统计学的推荐
- 根据推荐物品或内容的元数据,发现物品或者内容的相关性,这种被称为基于内容的推荐
- 根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,这种被称为基于协同过滤的推荐
根据推荐模型的建立方式
- 基于物品和用户本身的:将每个用户和每个物品都当作独立的实体,预测每个用户对于每个物品的喜好程度
- 基于关联规则的推荐:关联规则的挖掘已经是数据挖掘中的一个经典的问题,主要是挖掘一些数据的依赖关系,典型的场景就是“购物篮问题”
- 基于模型的推荐:这是一个典型的机器学习的问题,可以将已有的用户喜好信息作为训练样本,训练出一个预测用户喜好的模型,这样以后用户在进入系统,可以基于此模型计算推荐
深入推荐机制
本部分深入描述各个推荐机制的工作原理
基于人口统计学的推荐
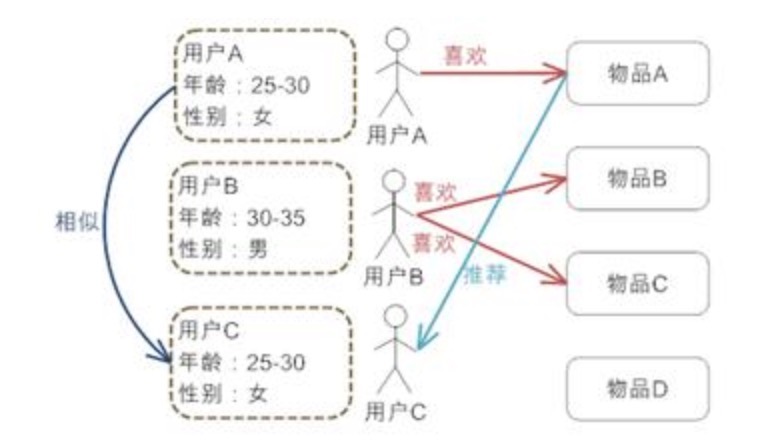
方法:
- 对每个用户有用户
Profile的建模 - 根据
Profile计算用户的相似度 - 基于邻居用户的喜好推荐给当前用户一些物品
好处:
- 不使用当前用户对物品的喜好历史数据,所以对于新用户来讲没有“冷启动(Cold Start)”的问题。
- 不依赖于物品本身的数据,所以这个方法在不同物品的领域都可以使用,它是领域独立的
缺点:
- 过于粗糙,无法起到很好的推荐效果
- 可能涉及到一些与信息发现问题本身无关却比较敏感的信息,比如用户的年龄等,不好获取
基于内容的推荐
核心思想是根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品
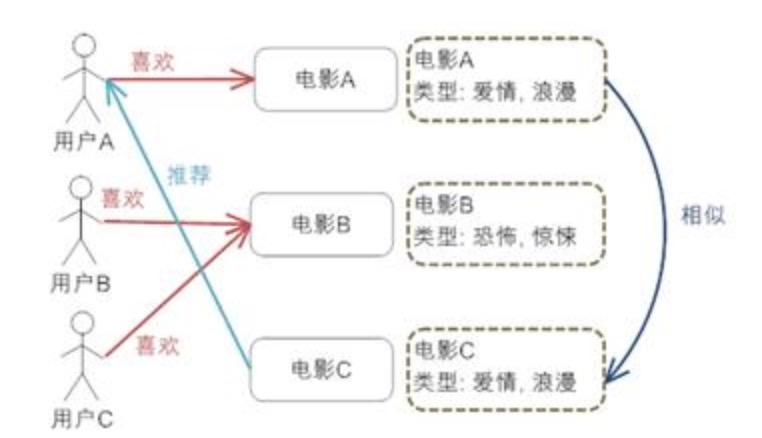
方法:
- 对电影元数据进行建模
- 通过电影元数据发现电影间的相似度
- 最后实现推荐,对于用户A,喜欢看电影A,就可以推荐电影C
好处:
- 它能很好的建模用户的口味
- 能提供更加精确的推荐
缺点:
- 需要对物品进行分析和建模,推荐的质量依赖于对物品模型的完整和全面程度
- 物品相似度的分析仅仅依赖于物品本身的特征,这里没有考虑人对物品的态度
- 因为需要基于用户以往的喜好历史做出推荐,所以对于新用户有“冷启动”的问题
主要应用在电影,音乐,图书的社交站点
基于协同过滤的推荐
原理:就是根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐
基于用户的协同过滤推荐
原理:根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,一般采用计算K-邻居算法
基本假设:喜欢类似物品的用户可能有相同或者相似的口味和偏好
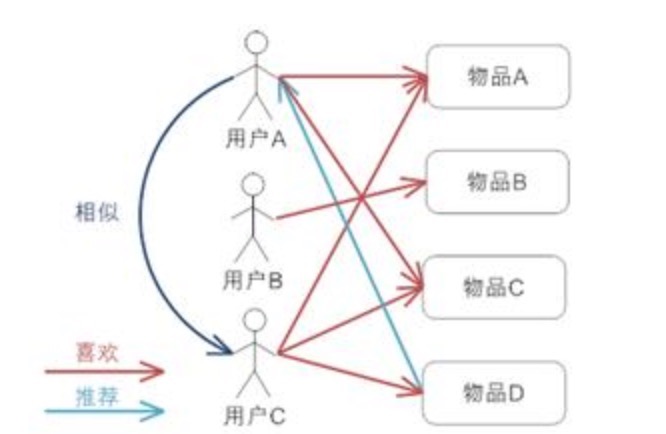
方法:
- 假设用户A喜欢物品A、C。用户B喜欢物品B,用户C喜欢物品A、物品C和物品D
- 可以判断用户A、C喜好接近,可以将物品D推荐给用户A
与基于人口统计学的统建机制的相似与区别:
- 相似:都是计算用户相似度,基于邻居用户群计算推荐
- 区别:基于人口只考虑用户本身特征,基于用户是在历史偏好上计算用户相似度
基于项目的协同过滤推荐
原理类似:使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户
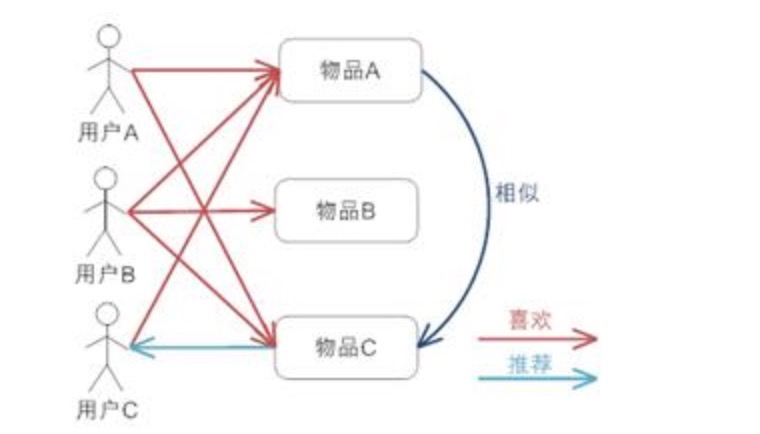
方法:
- 假设用户A喜欢物品A、C,用户B喜欢物品A、B、C,用户C喜欢物品A
- 从用户喜好可以发现物品A和C是比较类似的,喜欢A的都会喜欢C
- 系统将物品C推荐给用户C
基于项目的协同过滤推荐和基于内容的推荐其实都是基于物品相似度预测推荐,只是相似度计算的方法不一样,前者是从用户历史的偏好推断,而后者是基于物品本身的属性特征信息。
场景:
- 基于项目的协同过滤推荐机制是Amazon在基于用户的机制上改良的一种策略
- 在大部分的 Web 站点中,物品的个数是远远小于用户的数量的
- 物品的个数和相似度相对比较稳定
- 基于项目的机制比基于用户的实时性更好一些
基于模型的协同过滤推荐
原理:基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测,计算推荐。
优点:
- 它不需要对物品或者用户进行严格的建模,而且不要求物品的描述是机器可理解的,领域无关
- 这种方法计算出来的推荐是开放的,可以共用他人的经验,很好的支持用户发现潜在的兴趣偏好
问题:
- 方法的核心是基于历史数据,所以对新物品和新用户都有“冷启动”的问题。
- 推荐的效果依赖于用户历史偏好数据的多少和准确性。
- 在大部分的实现中,用户历史偏好是用稀疏矩阵进行存储的,而稀疏矩阵上的计算有些明显的问题,包括可能少部分人的错误偏好会对推荐的准确度有很大的影响等等。
- 对于一些特殊品味的用户不能给予很好的推荐。
- 由于以历史数据为基础,抓取和建模用户的偏好后,很难修改或者根据用户的使用演变,从而导致这个方法不够灵活。
混合的推荐机制
这里提供比较流行的方法去组合各个推荐机制
- 加权的混合:用线性公式将集中不同的推荐按照一定权重组合起来,权重需要测试与实现
- 切换的混合:允许不同的情况,选择合适的推荐计算机制
- 分区的混合:采用多种推荐机制,将不同的推荐结果分区显示给用户
- 分层的混合:采用多种推荐机制,并将一个推荐机制的结果作为另一个推荐的输入,得到更精确的推荐
推荐引擎的应用
推荐在电子商务中的应用 – Amazon
Amazon 利用可以记录的所有用户在站点上的行为,根据不同数据的特点对它们进行处理,并分成不同区为用户推送推荐:
- 今日推荐:通常是根据用户的近期的历史购买或者查看记录,并结合时下流行的物品给出一个折中的推荐。
- 新产品的推荐:采用了基于内容的推荐机制,将一些新到物品推荐给用户。
- 捆绑销售:采用数据挖掘技术对用户的购买行为进行分析,找到经常被一起或同一个人购买的物品集,进行捆绑销售,这是一种典型的基于项目的协同过滤推荐机制。
- 别人购买 / 浏览的商品:这也是一个典型的基于项目的协同过滤推荐的应用,通过社会化机制用户能更快更方便的找到自己感兴趣的物品。
Amazon特别的亮点:量化推荐原因
- 基于社会化的推荐,给出数据,让人信服,例如:购买此物品的用户百分之xx也购买了那个物品
- 基于物品本身的推荐,给出推荐理由,例如:因为你的购物框有A,所以推荐B
推荐在社交网站中的应用 – 豆瓣
- 当将看过或者感兴趣的电影加入列表后,就会展示电影推荐
- 豆瓣必然是基于社会化的协同过滤的推荐