写在前面的话
本文的主要内容是ddia的第六章,分区
分区的主要目的是在数据量极大时,单节点处理不可取,因此需要将数据分散到多个节点进行并行的处理,这样就引出了分散数据的方法的问题,分别有按照键的范围分区以及按照键的散列分区。
分区之后的次级索引的需求,引出了基于文档的分区以及基于关键词的分区,前者是本地索引,后者是全局索引。
在分区之后对于节点动态增加和删除的情况下,引出了分区平衡的问题,给出了一定的解决方案。
最后,对于请求路由,发现服务进行了介绍,提到了ZooKeeper,这个很有趣,在fabric kafka共识中,也是使用的zk来维护kafka的集群信息注册,不过当时并没有细细研究这个东西,之后有时间可以研究下fabric上的zk和kafka.
整体来说分区还是和复制结合使用的一种策略,不过又是完全独立的,区块链中公链很少分区,强行要扯上去可能是侧链的概念与分区有一定关系吧,更多还是复制。
分区
对于非常大的数据集或者非常高的吞吐量,仅仅复制是不够的,还需要对数据进行分区(partitions),也称为分片(sharding)
分区是一种有意将大型数据库分解成小型数据库的方式。它与网络分区(net splits)无关
通常情况下,每条数据属于且仅属于一个分区,分区的主要目的是为了可扩展性。
分区与复制
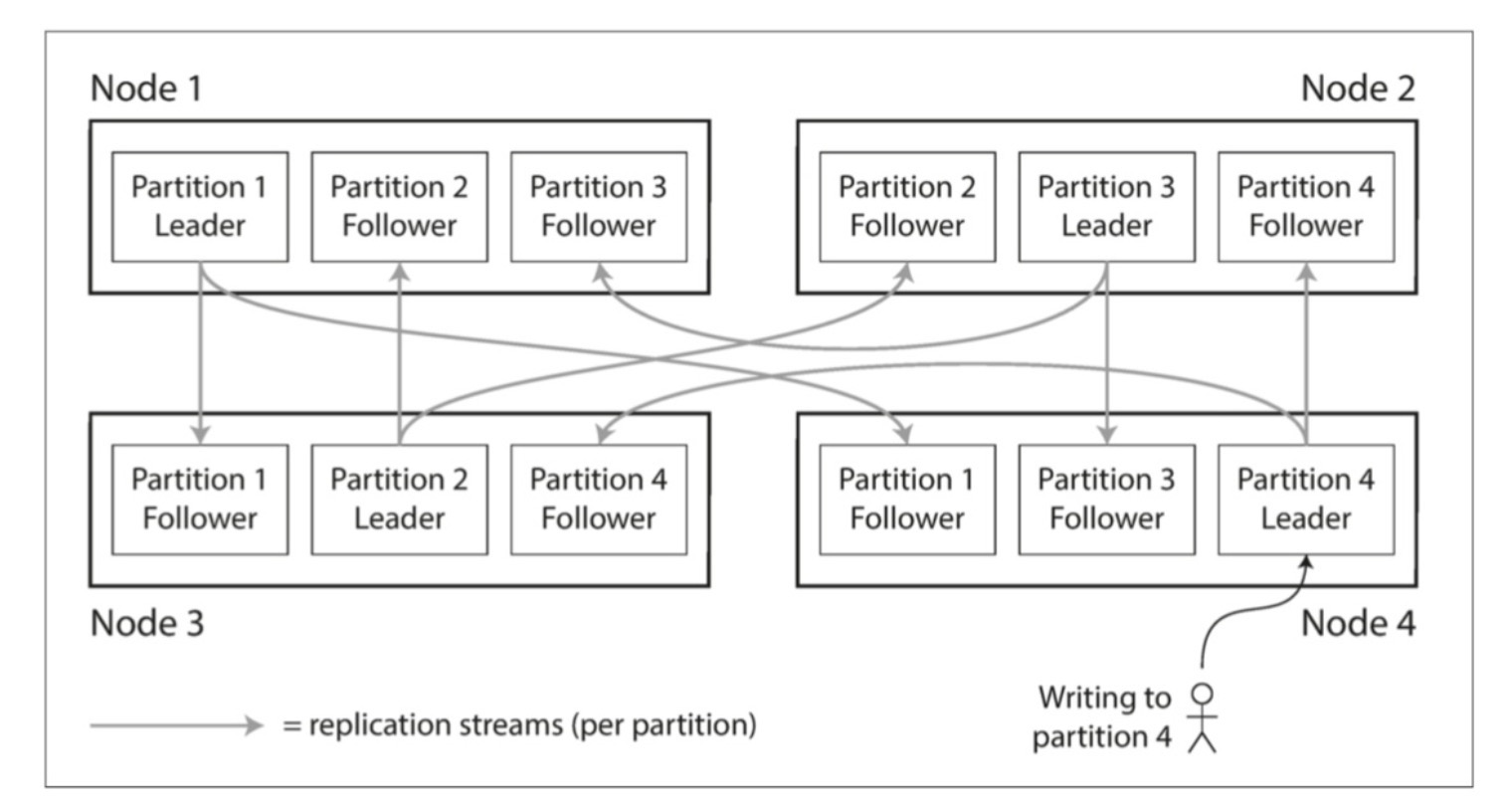
分区与复制通常可以结合使用,使得每个分区副本存储在多个节点上,大多数情况下,分区与复制的方案选择是独立的。
键值数据的分区
分区的核心是公平,尽量避免热点,最简单的方案就是将记录随机分配给节点,缺陷在于必须并行的查询所有节点。
根据键的范围分区
例如字典、百科全书的卷,知道范围之间的边界,就可以轻松确定哪个分区包含某个值。
分区边界会是一个问题,这里可以
- 管理员手动选择
- 数据库自动选择
在每个分区中,可以按照一定的顺序保存键(如SSTable和LSM)
- 好处:范围扫描简单
- 坏处:特定的访问会导致热点
例如:将测量数据存入数据库时,如果以时间戳为key,每天的数据写入都会产生一个热点,所有的数据都会写到当天存储所在的那个节点上,这里解决方案是需要使用除了时间戳以外的东西作为主键,例如传感器名称等。
根据键的散列分区
使用标准散列函数可以将偏斜的数据均匀分布。
一致性哈希
它使用随机选择的分区边界(partition boundaries)来避免中央控制或分布式一致性的需要,此处与复制一致性或ACID一致性无关。可以简单称之为散列分区(hash partitioning)
散列的劣势在于失去了高效执行范围查询的能力
举例:
- 在mongoDB中,如果使用了基于散列的分区模式,则任何范围查询都必须发送到所有分区
- Riak,Couchbase或Voldemort不支持主键上的范围查询
- Cassandra采用了折中策略,可以使用多个列的复合主键,只有第一列会作为散列的依据,其他列会被作为排序数据的连接索引,在第一列已经指定了固定值的情况下,可以对该键的其他列执行有效的范围查询
负载倾斜与消除热点
哈希分区可以减少热点,但是并不能避免,极端情况下所有读写操作都是针对同一个键的。
简单的处理方法:
在主键的开始或者结尾增加一个随机数
- 优势:这样可以将主键散列到不同的分区中
- 劣势:所有的读取都要做额外的合并操作,并且需要记录哪些主键被附加了随机数,这里需要自己来权衡。
分片与次级索引
次级索引是关系型数据库的基础,并且在文档数据库中也很常见,然而面临的问题是次级索引不能整齐的映射到分区,有两种用次级索引对数据库进行分区的方法
- 基于文档的分区
- 基于关键词的分区
基于文档的分区
例如某一汽车网站,每个列表都有一个唯一的文档ID,当需要按照颜色过滤时,需要构建一个颜色相关的次级索引,如下图所示
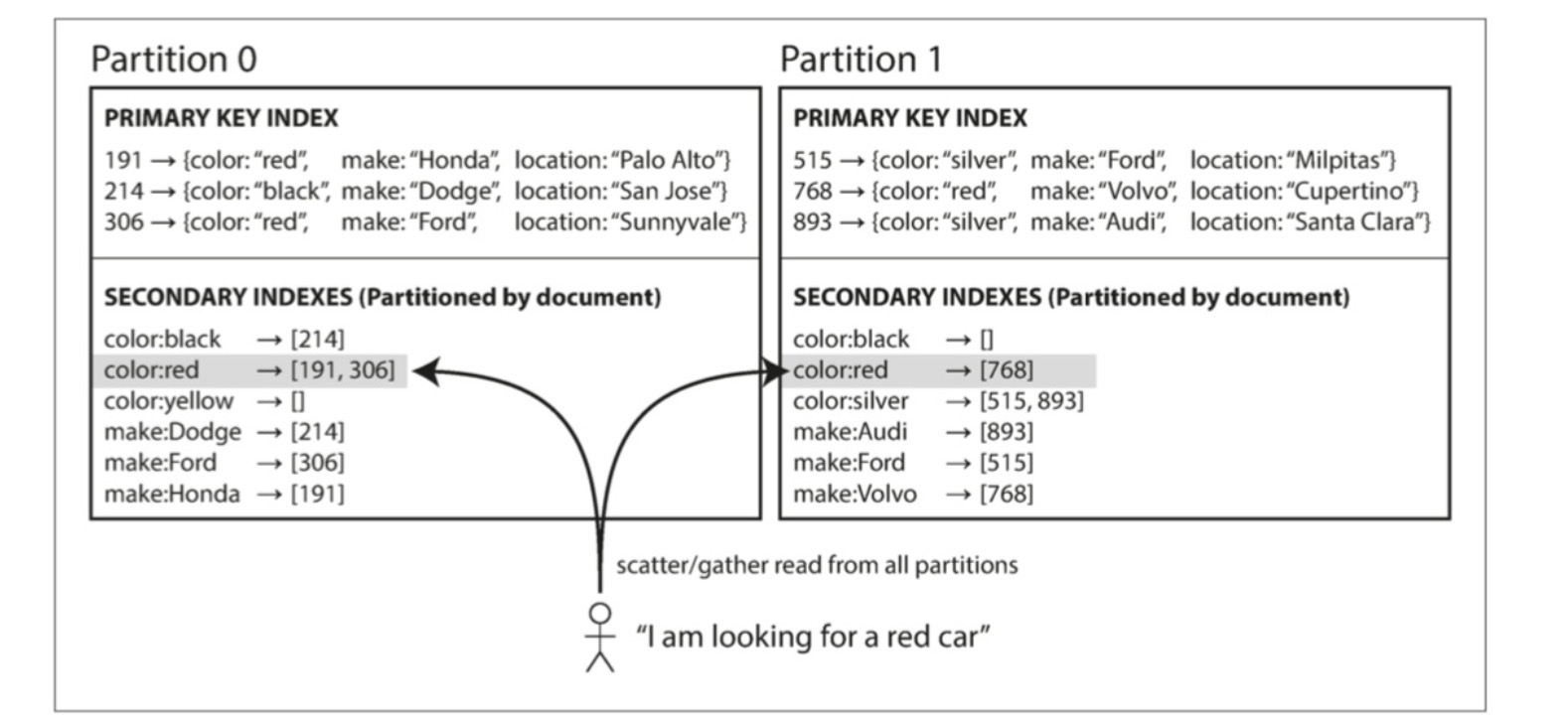
在这种索引方法中,每个分区是完全独立的:
- 分区维护自己的二级索引
- 不关心存储在其他分区的数据
因此也被称为本地索引
在查询时需要将请求发送到所有分区,并且合并所有返回的结果,因此也被成为分散/聚集。
使用:
- MonDBDB,Riak,Cassandra等
根据关键词的分区
构建一个全局索引,然后对索引也进行分区,如下图所示
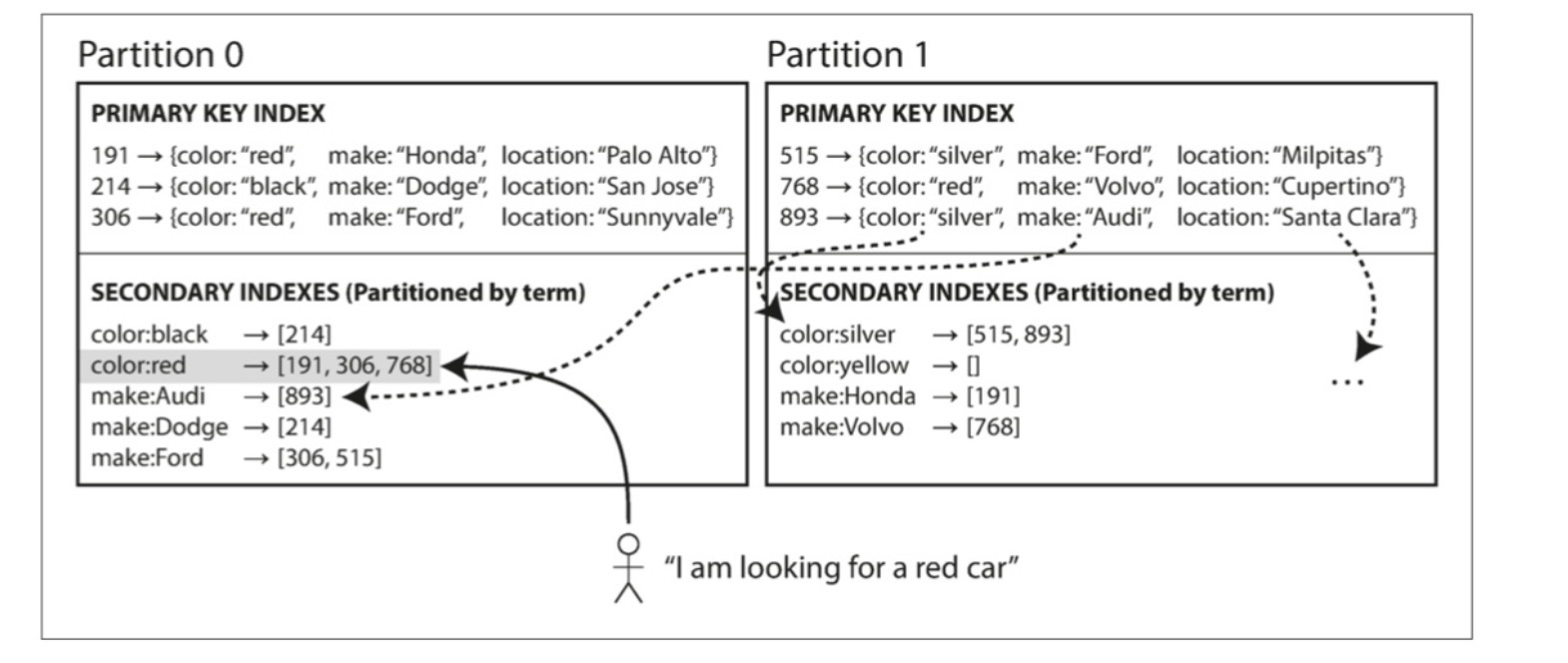
例如a到r的颜色在分区0中,s到z的在分区1中,等等
这种分区方式被称为关键词分区
优势
- 读取更有效率,不需要分散/聚集所有分区
劣势
- 写速度较慢且复杂,写入单个文档可能会影响索引的多个分区
理想情况下索引总是最新的,然而实践中对全局二级索引的更新通常是异步的。
分区再平衡
随着时间推移,数据库会产生变化,例如需要更多的CPU来处理吞吐量,更多的磁盘存储数据集等,这些需要数据/请求从一个节点移动到另一个节点。这种将负载从集群中的一个节点向另一个节点移动的过程称为再平衡
再平衡的最低要求
- 再平衡后,负载应该在集群中的节点之间公平的共享
- 再平衡发生时,数据库应该继续接受读取和写入
- 节点之间只移动必须的数据,以便快速再平衡,并减少网络和磁盘I/O的负载
平衡策略
hash mod N:极不推荐
方法:hash(key) mode 10,就可以简单的将键分给了10个节点
劣势:如果N(节点数量)发生了变化,就会导致大量的数据发生了移动,这使重新平衡过于昂贵了。
固定数量的分区
简单解决方案:创建比节点更多的分区,并为每个节点分配多个分区
例如:
- 运行在10个节点上的集群开始被拆为1000个分区,大约会有100个分区分配给每个节点
- 当节点被添加集群后,从之前的节点中窃取分区,知道分区再次公平分配
- 只有分区在节点间移动,分区的数量和键不会被改变
缺陷:
分区数量固定 ,但是数量量变动很大,难以达到最佳性能。
动态分区
分区增长到超过配置的大小时,会被分成两个分区,每个分区约占一半的数据。相反,如果大量数据被删除分区缩小到某个阈值以下,就可以和相邻分区合并。
注意点:
当空数据库从一个分区开始,所有写入就会汇集到一个节点,因此允许在一个空数据库上预先配置一组初始分区(预分割,HBase和MongoDB)
不仅使用于范围分区,也适用于散列分区
按节点比例分区
每个节点具有固定数量的分区。
- 每个分区大小与数据集大小成比例增长,而节点数量保持不变
- 当增加节点数时,分区将再次变小
- 新节点加入会随机选择固定数量的现有分区进行拆分,占有一半并且将另一半留在原地
要求使用基于散列的分区
运维:手动还是自动平衡
- 全自动平衡:系统自动决定何时将分区从一个节点移到另一个节点,无需人工干预
- 优势:方便,正常维护少
- 劣势:不可预测,可能危险。
- 完全手动:分区指派给节点由管理员明确配置,仅在管理员明确重新配置时才会更改。
例如:
假设一个节点过载,并且对请求的响应暂时很慢。其他节点得出结论:过载的节点已经死亡,并自动重新平衡集群,使负载离开它。这会对已经超负荷的节点,其他节点和网络造成额外的负载,从而使情况变得更糟,并可能导致级联失败。
请求路由
可以概括为服务发现,如下图所示:
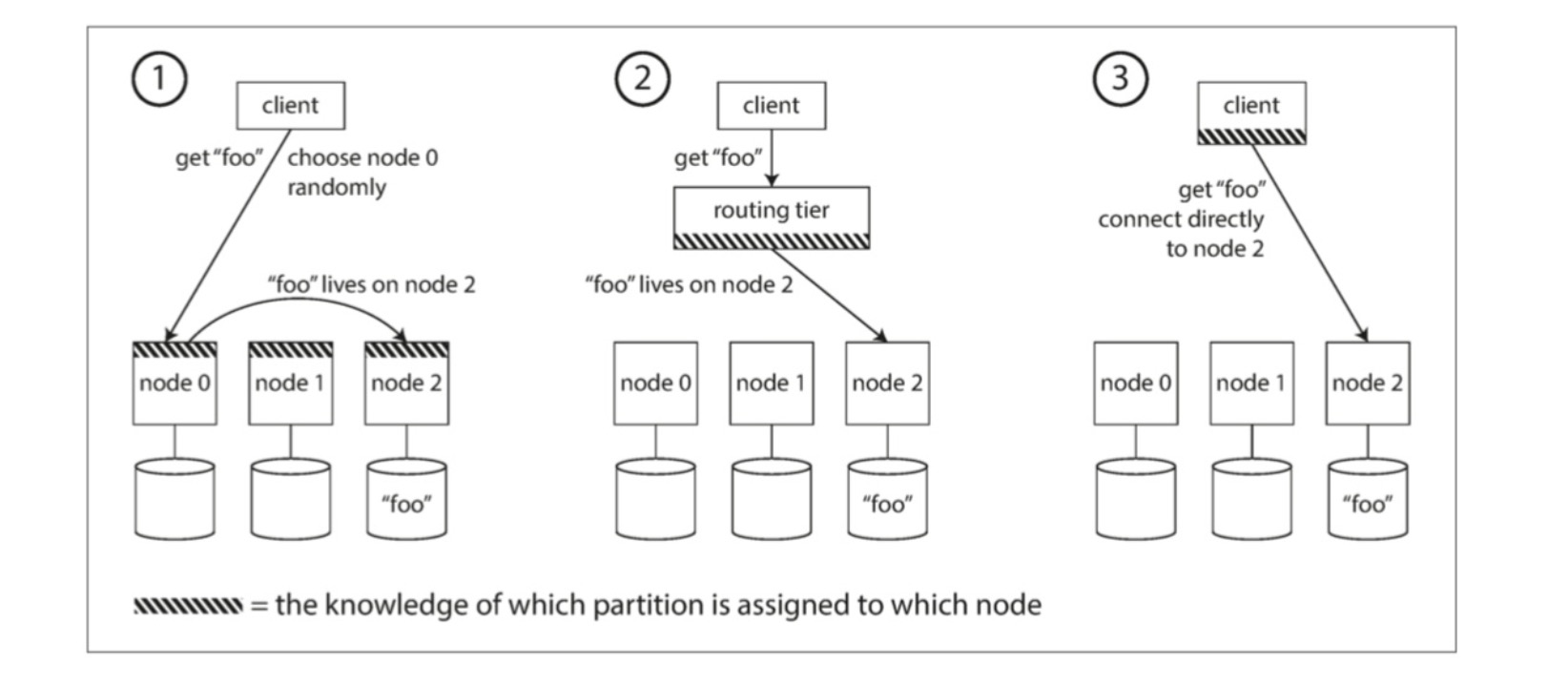
- 允许联系任何节点,如节点拥有分区,则直接处理该请求,否则将请求转发,接收回复并传递给客户端
- 将请求发送到路由层,决定应该请求的节点,并相应的转发
- 要求客户端知道分区与节点的配置,客户端直接连接,不需要中介。
问题:路由决策的组件是如何了解分区-节点之间的分配关系变化的?
许多都依赖于一个独立的协调服务,如ZooKeeper来跟踪集群元数据。
- 每个节点都在ZooKeeper中注册自己
- ZooKeeper维护分区到节点的可靠映射
- 参与者可以在ZooKeeper中订阅此信息,当分区发生改变,就会ZK就会通知路由更新。
执行并查询
大规模并行处理(MPP, Massively parallel processing)