动机
在了解了底层的kad网络后,明确了基础的网络存储方案以及发现方法,但是我们还是不清楚在以太坊中底层的网络层是如何运作的,毕竟上层应用其实根本不关注下层网络层的运转,而是直接调用各种节点信息进行点对点通信。
基础结构
首先我们关注网络层的基础结构
1 | type Server struct { |
1 | type Config struct { |
从基础结构可以看出来,整个网络层核心做的事情主要有三件
- 对网络发现表(K桶)的管理
- 与节点连接进行管理
- 对底层网络消息协议进行处理,并且执行对应操作
服务启动流程
接下来我们关注一下整个server在启动时会做哪些事情,server的启动是通过server.Start()方法进行启动的,在这部分我们将对此进行分析
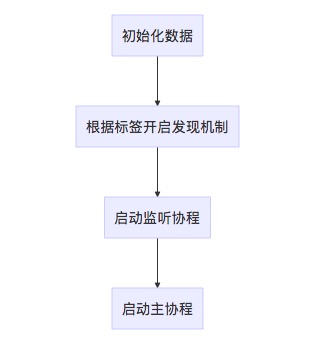
接下来我们就开始一个一个分析每部分做了啥
初始化数据
1 | // 初始化 |
可以看到初始化的时期主要是对协议和初始连接进行了配置,设置默认协议为newRLPX,连接为net.Dialer
发现机制
1 | // 发现机制 |
发现机制在这个版本的以太坊中实现了两种,一种是普通版本的发现机制,另外一种是v5版本的发现机制,这个发现机制就是严格的按照KAD网络实现的一个基础K桶操作,具体内容可以看之前的kad网络实现机制
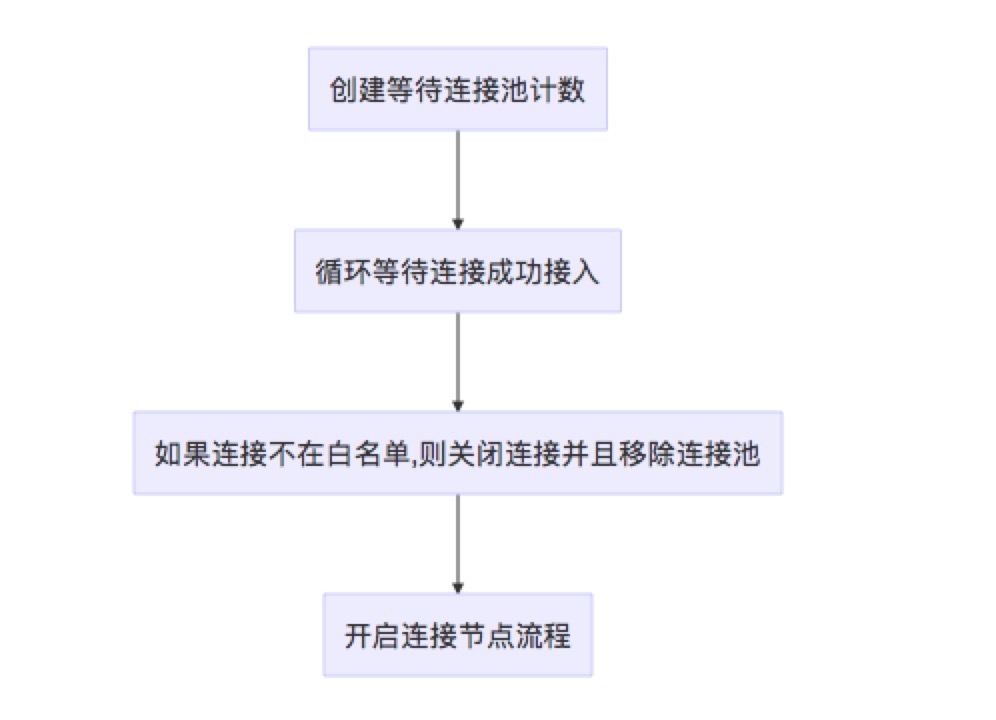
监听协程
1 | func (srv *Server) listenLoop() { |
监听协程其实本质上是给一些连接比较慢的节点一些连接机会,容忍一些普通的错误,并且对于限制名单进行处理,如果不满足限制名单则关闭连接。对于这个连接机会同样开启了一个数量限制,等待连接中的连接数不能超过太多。当连接能够被允许时,则运行srv.SetupConn来接受连接,开始连接流程。
简单流程图如下:
主协程
主协程做的事情稍微多一些,以下是简单的流程图
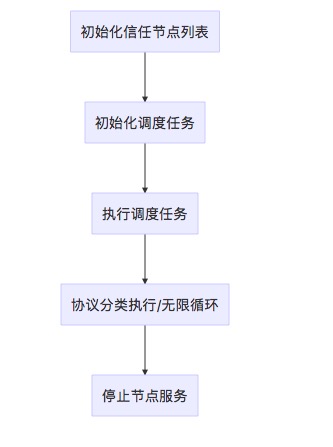
调度任务的执行是比较简单的1
2
3
4
5
6
7
8
9
10// 调度任务
scheduleTasks := func() {
// Start from queue first.
queuedTasks = append(queuedTasks[:0], startTasks(queuedTasks)...)
// Query dialer for new tasks and start as many as possible now.
if len(runningTasks) < maxActiveDialTasks {
nt := dialstate.newTasks(len(runningTasks)+len(queuedTasks), peers, time.Now())
queuedTasks = append(queuedTasks, startTasks(nt)...)
}
}
当任务队列数量不满时,就会生成一个newTasks并且执行之,保证整个主协程一直有任务在执行
协议分类执行的分支相对较多,以下是具体的分类协议
- 服务退出
- 增加静态节点
- 移除静态节点
- 节点操作
- 任务完成
- 握手连接
- 增加节点
- 删除节点
节点管理
接下来我们关注整个流程中如何来管理节点的
节点管理整体上来看是两个部分,扩充预备的节点数量以及对已经发现的节点进行存储
扩充节点数量
整体的服务中与节点相关的主要是如下接口
1 | type discoverTable interface { |
整体流程还是通过发现任务和KAD基础网络,在添加节点上最核心的方法在于lookup
1 | func (tab *Table) lookup(targetID NodeID, refreshIfEmpty bool) []*Node { |
整体流程图如下
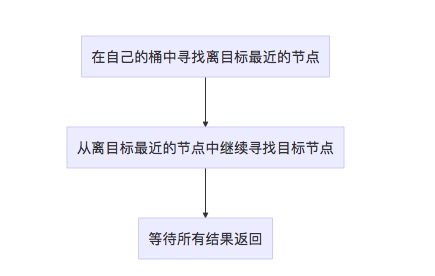
调用lookup的地方我们也能看到,是在发现任务时随机生成一个目标节点,然后去发现这个目标节点,通过找到周边节点来扩充节点的数量
1 | func (t *discoverTask) Do(srv *Server) { |
节点存储
当在内存中的发现节点连接时间超过最小连接时间后,会触发copyBondedNodes方法,将内存中的发现数据存储到leveldb中。
1 | func (tab *Table) copyBondedNodes() { |
最终的存储结构如下代码所示
1 | func (db *nodeDB) updateNode(node *Node) error { |
可以看到,这个存储是完全周期性的将内存中满足条件(主要是连接时间)的节点存储到数据库中的。
协议处理
协议处理分为两种类型,一种是初始创建连接时,这里的代表就是addpeer,另一种就是连接已经通顺之后的数据通信,例如KAD网络的基础操作PING,FINDNODE等
add peer
之前在服务启动的时候提到,当一个连接到来之后满足要求后会触发SetupConn方法,add peer就是在这个方法中完成的。
整体流程如下
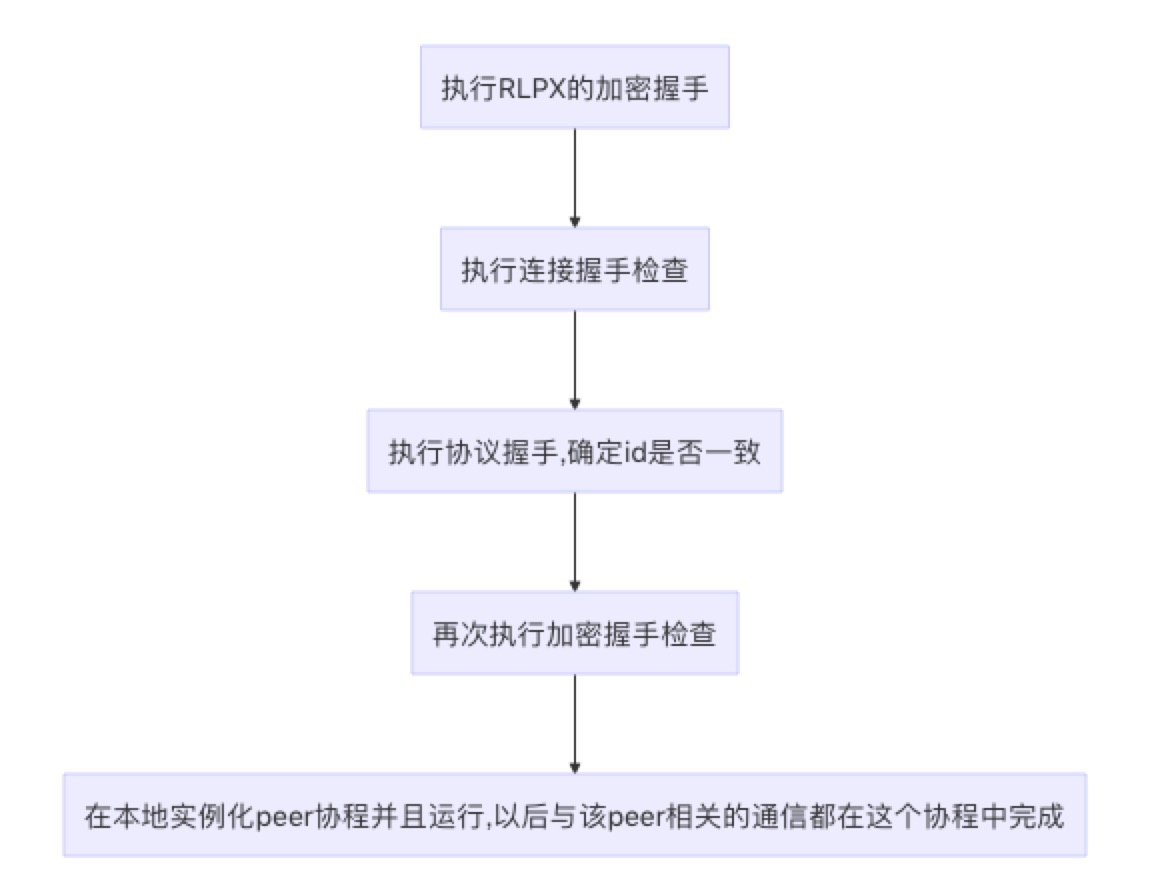
可以看到,add peer前期主要是做一些握手检查,然后在确认可以连接之后启动了peer协程,通过readLoop协程一直接收来自该peer的信息。
普通操作
这里我们以findnode为例
发包
发包的核心其实就在于p2p.Send方法
收取包
从readloop可以看到,这里调用的是协议transport中的ReadMsg方法,从这里可以辗转得到实际ReadMsg的方法为func (rw *rlpxFrameRW) ReadMsg() (msg Msg, err error)
这里就不展开了,通过ReadMsg的解包后进入了handle方法,如果是ping方法,就在这一层进行了处理,如果是子协议,就开始在更高层的protocal.Run方法进行处理,这里有兴趣可以关注func NewProtocolManager(config *params.ChainConfig, mode downloader.SyncMode, networkId uint64, mux *event.TypeMux, txpool txPool, engine consensus.Engine, blockchain *core.BlockChain, chaindb ethdb.Database) (*ProtocolManager, error)
这里所写的各种协议
总结
这里我们可以看到整体来说p2p的server层结构还是很清晰的,Server.go来管理整体的服务,Peer.go是对每个连接上的节点数据进行管理和处理,Message.goy终于处理整体的消息结构体,rlpx是最底层的协议,dail.go维护任务执行,discover模块实现了KAD网络。总的来说就是基于KAD网络的一个基础模块