概述
源自论文 《Kademlia: A peer-to-peer information system based onthe XOR metric》 https://pdos.csail.mit.edu/~petar/papers/maymounkov-kademlia-lncs.pdf
Kademlia算法是一种通过分布式哈希表(DHT)技术实现的协议算法,Kad算法通过独特的以异或算法(XOR)为距离度量基础,建立了一种全新的DHT拓扑结构,相比于其他算法,大大提高了路由查询速度。
- 通讯方式:UDP
- 身份标识:一组数字(节点ID),同样用来进行值定位
- 搜索方式:
- 知道与这些值的相关键
- 分布在网络开始搜索
- 搜索到节点的ID直接返回搜索值或者无法再找到与键更接近的节点ID时停止搜索
- 仅能访问O(log(n))个节点
选择XOR的原始是通过它计算的距离享有几何距离公式的一些特征
- 节点和它本身之间的异或距离是0
- 异或距离是对称的:即从A到B的异或距离与从B到A的异或距离是等同的
- 异或距离符合三角形不等式:给定三个顶点A、B、C,假如AC之间的XOR距离最大,那么AC之间的XOR距离必小于或等于AB XOR距离和BC XOR距离之和.
接下来详细分析在以太坊p2p网络中对于kad协议的实现。
路由表
基本原理
在kad网络中,路由表是由:
- 1.多个列表,每个列表对应节点ID的一位
2.包含多个条目,条目中包含定位其他节点所必要的一些数据
- 2.1 IP地址,
- 2.2 端口
- 2.3 节点ID
3.节点的第n个列表中所找到的节点的第n位与该节点的第n位肯定不同,而前n-1位相同
- 4.列表的容量是由系统变量决定的(又被称为K桶)
- 5.当K桶满时,又发现了新的节点
- 5.1 首先检查K桶中最早访问的节点
- 5.2 假如该节点仍然存活:新节点就被安排到一个附属列表中
- 5.3 假如该节点停止响应:替代cache才被使用
- 5.4 新发现的节点只有在老的节点消失后才被使用
以太坊实现
主要代码位于 p2p/discover/table.go中:
节点数据结构1
2
3
4
5
6
7
8
9type Node struct {
IP net.IP // 节点IP
UDP, TCP uint16 // 节点端口
ID NodeID // 节点公钥
sha common.Hash //节点ID的sha3 hash,用于计算节点距离
addedAt time.Time //节点被加入到网络表的时间
}
桶的数据结构1
2
3
4
5type bucket struct {
entries []*Node // 目前存活的节点,根据活跃度排序
replacements []*Node // 缓存中的可能被用于替换的节点
ips netutil.DistinctNetSet // 可能的前缀集
}
1 | // 发现表的数据结构 |
1 |
|
1 | // 此处删除了db中的老旧的不响应节点,对应5.4 |
协议消息
原理
一共有四种协议消息
- PING:用来测试节点是否在线
- STORE:在某个节点中存储一个键值对
- FIND_NODE:消息请求的接收者将返回自己桶中离请求键值最近的K个节点
- FIND_VALUE:消息请求的接收者将返回自己桶中相应键的值
- 每一个RPC消息中都包含一个发起者加入的随机值,这一点确保响应消息在收到的时候能够与前面发送的请求消息匹配。
以太坊实现
主要代码位于p2p/discover/udp.go中:
整体的upd包在loop()中拿到消息放在队列中,在readLoop对包进行rlp解析以及处理
1 | // 此处实现了 1 中的PING方法 |
1 | // 此处实现了3中的FIND_NODE方法 |
定位节点
原理
获得局部网络中离被搜索键值最近的K个节点
- 可以同步查询,也可以异步查询
- 向自己K桶中离所查询的键值最近的K个节发起FIND_NODE请求
- 请求接受者在收到消息后在自己K桶查询,如果他们知道离被查键更近的节点,他们就返回这些节点(最多K个)
- 请求者收到响应后用响应结果来更新它的结果列表,这个结果列表保持K个响应FIND_NODE消息请求的最优节点
- 果本次响应结果中的节点没有比前次响应结果中的节点离被搜索键值更近了,这个查询迭代也就终止了
以太坊实现
定位资源
原理
- 通过把资源信息与键进行映射,资源即可进行定位。
- 定位资源时,如果一个节点存有相应的资源的值的时候,它就返回该资源,搜索便结束了,除了该点以外,定位资源与定位离键最近的节点的过程相似。
以太坊实现
加入网络
原理
想要加入网络的节点首先要经历一个引导过程。在引导过程中,节点需要知道其他已加入该网络的某个节点的IP地址和端口号(可从用户或者存储的列表中获得)(bootnode)
- 正在加入kad网络的节点在它的某个K桶中插入引导节点
- 向它的引导节点发起NODE_LOOKUP操作请求来定位自己
- 这一自查询过程使得新加入节点自引导节点所在的那个K桶开始,由远及近,逐个得到刷新,这种刷新只需通过位于K桶范围内的一个随机键的定位便可达到。
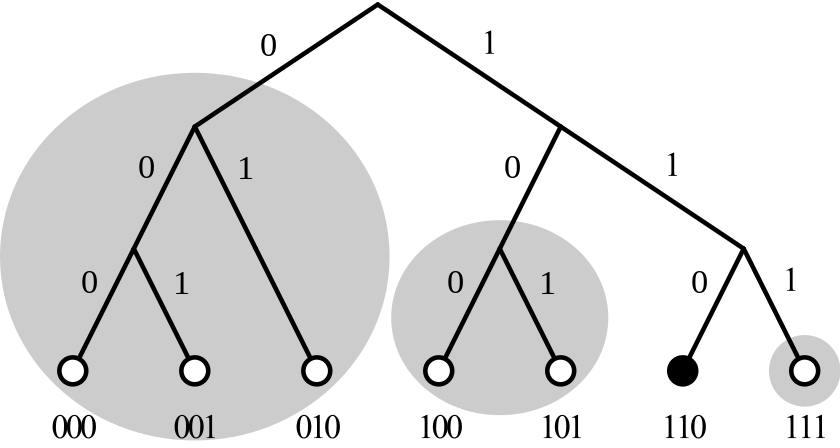
新节点的K桶分裂机制
- 节点仅有一个K桶(覆盖所有的ID范围),当有新节点需要插入该K桶时,如果K桶已满,K桶就开始分裂
- 分裂发生在节点的K桶的覆盖范围(表现为二叉树某部分从左至右的所有值)包含了该节点本身的ID的时候
[此处需要一个图来说明]
以太坊实现
1 | 通过初始化bootnode节点来对K桶插入引导节点 |
查询加速
原理
- Kademlia的路由表可以建在单个bit之上,即可使用位组(多个位联合)来构建路由表
- 位组可以用来表示相应的K桶,它有个专业术语叫做前缀,对一个m位的前缀来说,可对应2^m-1个K桶